
Какие факторы роста в сторах выявила модель машинного обучения на данных итераций

Оглавление
- Важная оговорка
- Результат итерации виден на следующий день
- Short Description важнее, чем Title
- Близкие по смыслу слова продвигают другие ключи
- Разбиение ключа из Title в Title+Subtitle дал 80% улучшений
- Точное вхождение ключа не обязательно
- Выводы
Откуда вообще взялись представления о том, что анализ ASO-итерации нужно делать через 2 недели, что связка Title+Keyword мэтчит лучше других комбинаций, а точное вхождение ключа почти автоматически дает больший прирост позиций?
Часть подобных установок в индустрии держится не на воспроизводимой статистике, а на наборе частных наблюдений, кейсов и экспертных интерпретаций, которые со временем начинают восприниматься как аксиомы. А уже под них подгоняют последующие результаты.
В результате рынок стагнирует и во многом превращается в гадание на кофейной гуще, где частный опыт подменяет собой доказательную базу. А вся доказательность сводится к “в гайдлайнах так написано”.
Обратная сторона в том, что эту логику дополнительно оборачивают в «у меня сработало, а у вас может не сработать».
За фразой действительно стоит рациональное зерно: на итог влияют десятки переменных – сам ключ, его интент, текущая позиция, конкурентное окружение, удержание, классификация, семантическая релевантность, в общем, множество дополнительных факторов, которые не всегда видны на поверхности.
В итоге, любая практика становится неопровержимой, любая ошибка – необъяснимой. Если любую закономерность заранее оправдывать тем, что «все слишком индивидуально», то это уже не аналитика, а удобная форма лени.
Именно поэтому в прошлом году я начал собирать и обучать модель машинного обучения на данных ASO-итераций. Ее задача в том, чтобы проверить, какие действия чаще связаны с улучшением или ухудшением позиций, а какие оказываются лишь статистической погрешностью.
И затем построить прогностическую модель, которая будет заранее знать, какие действия к каким результатам могут привести. А чтобы не застывать на полученных данных, она будет дообучаться на приложениях, с которыми работаем и повышать вероятность правильных решений.
По мере накопления полноценного датасета по отдельным языкам, странам и категориям это позволит постепенно переводить ASO из области «магических услуг» в более доказательное, проверяемое и прогнозируемое направление. Мы называем это ASO ENGINEERING. И каждый студент на курсе для специалистов уровня Middle+ вносит свой вклад в это.
Важная оговорка
Текущего массива данных пока недостаточно, чтобы объявить выявленные закономерности окончательным описанием того, как именно устроен механизм ранжирования в сторах.
Этот материал не дает оснований для догматических выводов и тем более не отменяет необходимость дальнейшей проверки на новых выборках. Но даже в таком виде массив уже позволяет увидеть повторяющиеся сигналы, которые выходят за пределы единичных совпадений.
Поэтому в этой статье речь пойдет не о секретных приемах и не о попытке выдать очередной набор частных кейсов за универсальный закон. Речь пойдет о паттернах, которые в текущем массиве данных встречались чаще других и коррелировали с более сильным или, наоборот, более слабым результатом.
Результат итерации виден на следующий день
Я не знаю откуда взялось, что анализ нужно проводить через 14 дней, но так научили, так привыкли. Хотя, читая ASO Приветы, вижу, что многие эксперты уже отходят от этого устоявшегося правила. И даже утверждают, что результаты могут появиться уже на следующий день.
Что ж, данные распределения позиций показывают, что изменения от обновления метаданных видны уже в первые дни. Критерий ≥5 п.п. доли в топ-20 за три дня подряд дал следующие медианы первых сдвигов:
App Store – 1 день (min 1, max 4)
Google Play – 3 дня (min 3, max 7)
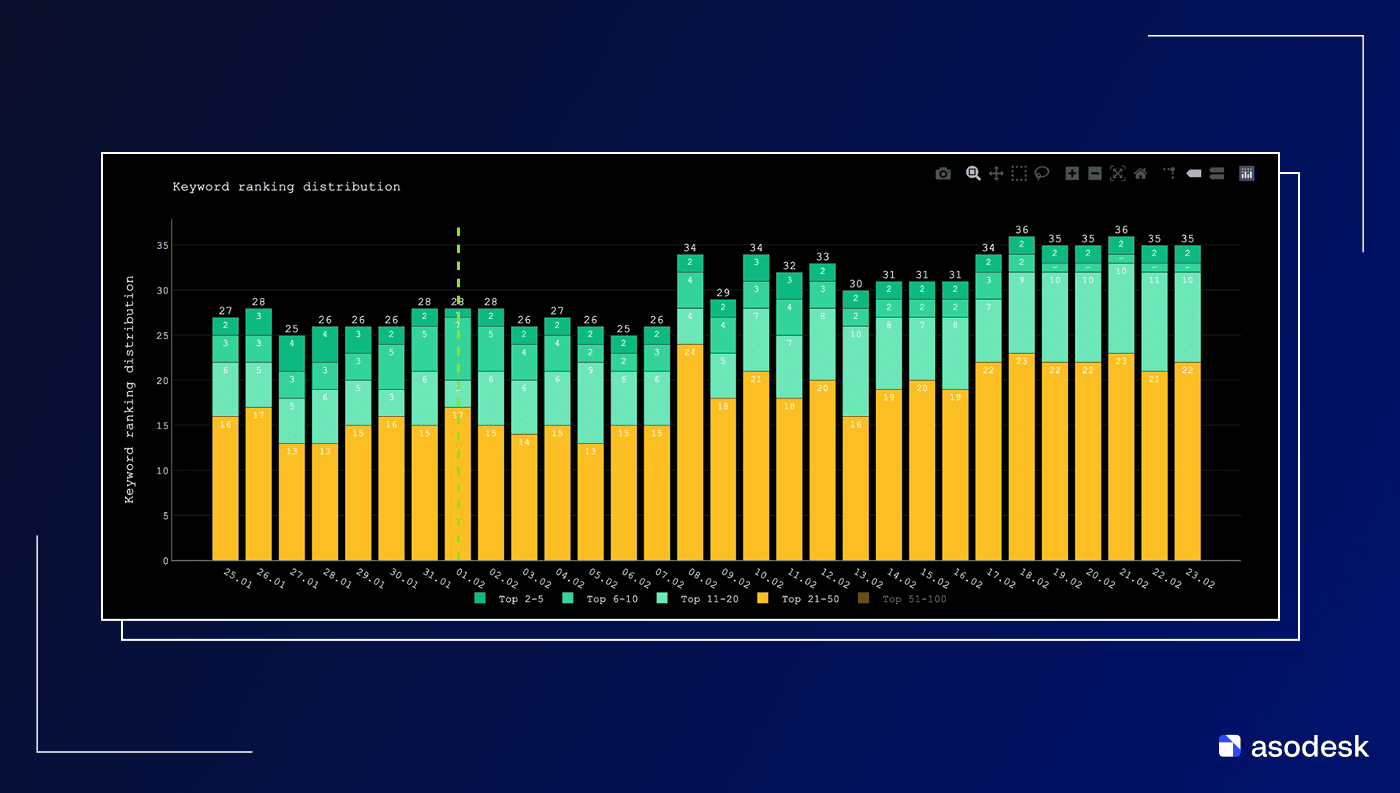
То есть в наших данных App Store показал сдвиги уже на следующий день после апдейта, а Google Play – примерно на 3-й день. И не просто сдвиги (просадка после обновления), а те, которые напрямую связаны с изменением метаданных.
Ждать у моря погоды в 2 недели не всегда имеет смысл. Иногда, действительно, нужно больше времени чтобы уточнить семантику приложения и в краткосрочной перспективе такие итерации даже бывают в ущерб. Но выигрывают в долгосрочной перспективе.
Short Description важнее, чем Title
В выборке Google Play анализировалось 512 итераций обновления метаданных, где измерялось изменение ранга по поисковому запросу. Базовый уровень улучшений здесь оказался ниже, чем в App Store: сильный рост позиции был зафиксирован только в 37,7% случаев.
Это связано с более сложной механикой ранжирования Google Play. В отличие от App Store, где влияние текстовых изменений в метаданных читается более прямо, в Google Play заметно выше роль факторов, которые не сводятся к буквальному вхождению ключа. Именно поэтому классическое ASO здесь чаще дает менее линейный и менее предсказуемый результат.
Важно отдельно подчеркнуть, что в эту выборку не включались наши текущие эксперименты, в которых ASO рассматривается в связке с SEO, GEO и AEO. Это было сделано намеренно, чтобы не смешивать разные механики и сохранить чистоту данных. Соответственно, все выводы этого раздела относятся только к классическим изменениям метаданных в Google Play.
Поля метаданных, участвующие в анализе: Title, Short Description и Full Description. Анализ включал ранжирование действий (Action ranking) с точки зрения их связи с улучшением позиций. Также учитывались признаки покрытия и типа совпадения.
Важно, что в имеющемся датасете метаданные обычно менялись частично. Поэтому не все факторы можно было проверить, данных было недостаточно.
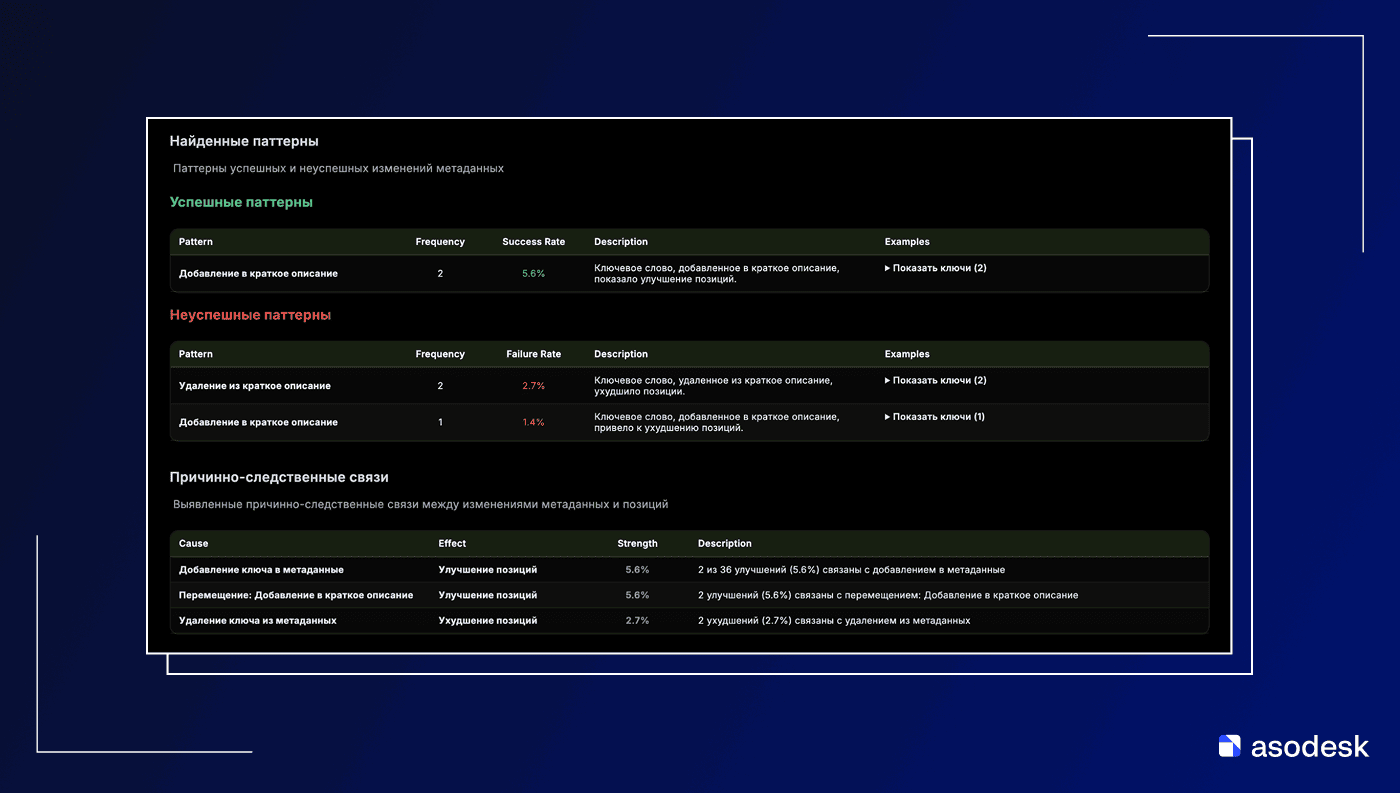
Главным устойчивым фактором роста в Google Play по функциональным ключевым словам выявилась работа с полем Short Description. Практически все паттерны, давшие наибольший рост позиций, связаны с тем, что ключевое слово появилось или переместилось в Short Description ~84,2%. Вне зависимости от начального ранга добавление ключа в Short Description чаще сопровождалось ростом, чем другие изменения.
Для сравнения: ключ в Full Description после изменений давал лишь ~40% улучшений, а ключ только в Title – и вовсе ~15,8% (может так хитро борятся с переспамом этого поля?).
- Только short_desc: 84.2% улучшений (+46.5 п.п.).
- Только title: лишь 15.8% (−21.9 п.п. ниже базы).
- Только full_desc: 40.5% (+2.8 п.п.).
- Ни в одном поле: 36.4% – близко к базе.
Интересно, что на качество итераций в положительную сторону влияло наличие дублей ключа в Full Description. 54,5% улучшений против базы 37,7%. Это +17 п.п. – не столь ярко, но показывает, что если ключ уже был в Full Description до обновления, это скорее помогало (возможно, благодаря общей релевантности приложения по этому запросу).
Впрочем, само по себе изменение Full Description после изменений Short Description не давал большого роста. Движение ключей было, но нам удалось отделить эти движения от влияние меты, чтобы точно знать что привело к движениям ключей.
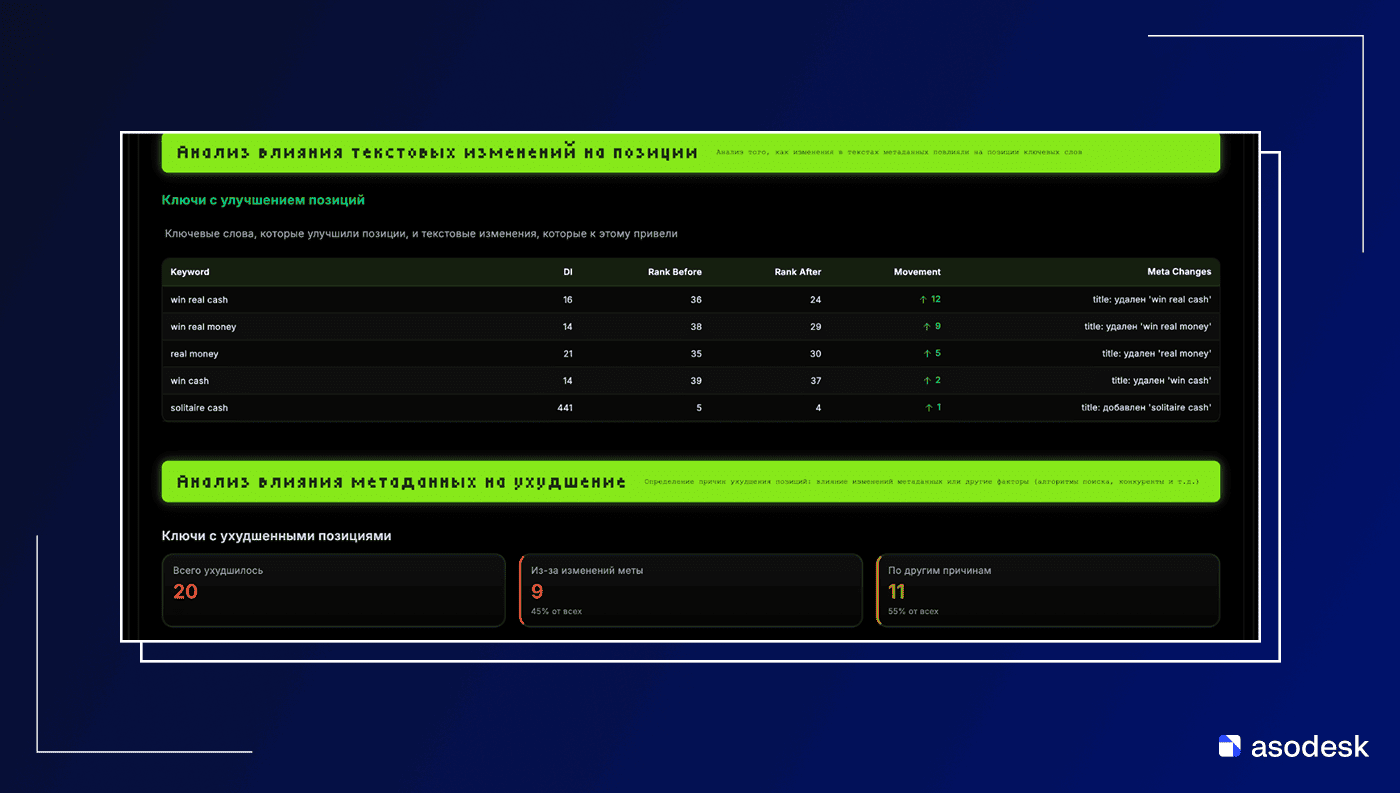
По негативным паттернам (просадка позиций) ситуация аналогичная: худшее, что можно было сделать – убрать ключ из Short Description. Сценарий moved_from_short_desc=True (ключ был в коротком описании, после изменений пропал оттуда) показал 0% улучшений.
Остальные факторы либо слабо отрицательные, либо отражают общее отсутствие позитивных изменений.
Близкие по смыслу слова продвигают другие ключи
В каждом случае фиксировалось, в каких полях (Title, Subtitle, Keywords) ключ присутствовал до и после изменения, и какой это тип совпадения – полное (exact), частичное (partial) или мягкое (soft) соответствие ключевой фразе.
На выборке App Store частичное покрытие ключа (partial/soft) в среднем связано с более высокой долей улучшений по сравнению с отсутствием ключа вовсе. Для понимания приведу пример:
Целевой ключ: strategy game
- Полное совпадение: strategy game(s). Ключ повторяется в метаданных целиком, без изменений.
- Частичное совпадение: strategy. В метаданных присутствует только часть ключевой фразы.
- Мягкое совпадение: tactical game. Прямого совпадения с ключом нет, но есть близкая по смыслу конструкция, которую система может учитывать как нестрогое совпадение.
Например, итерации, где ключ после изменения находился в метаданных частично (лемма), имели ~60% случаев улучшения при медиане подъема на 6 позиций.
Аналогично, если до изменения ключ уже присутствовал в метаданных частично, доля успешных исходов также ~60%. Эти признаки (partial/soft) выступают как позитивные сигналы, однако важно помнить: взаимосвязь носит корреляционный характер, а не гарантирует причинный эффект.
Кроме того, влияние типа вхождения варьируется по исходной позиции: скажем, в топ-выдаче (позиции 1–3) все итерации редки и успех маловероятен почти при любом типе, а в диапазоне позиций 11–20 в данных даже наблюдалось, что partial сработал хуже, чем вообще отсутствие ключа в метаданных (вероятно, из-за специфики конкуренции в этом сегменте). Поэтому тип покрытия нужно всегда сопоставлять с контекстом – начальным ранком (bucket) и конкуренцией. К сожалению, учитывать этот фактор я стал позже, когда выборка собралась уже достаточная.
Разбиение ключа из Title в Title+Subtitle дал 80% улучшений
Для App Store также анализировались различные разбивки ключа по полям: в одном поле, сразу в двух или во всех трех. Например, new_in_title+subtitle+keywords означает, что ключевого слова не было нигде до изменения, а после оно появилось разбитым на Title, Subtitle и Keywords.
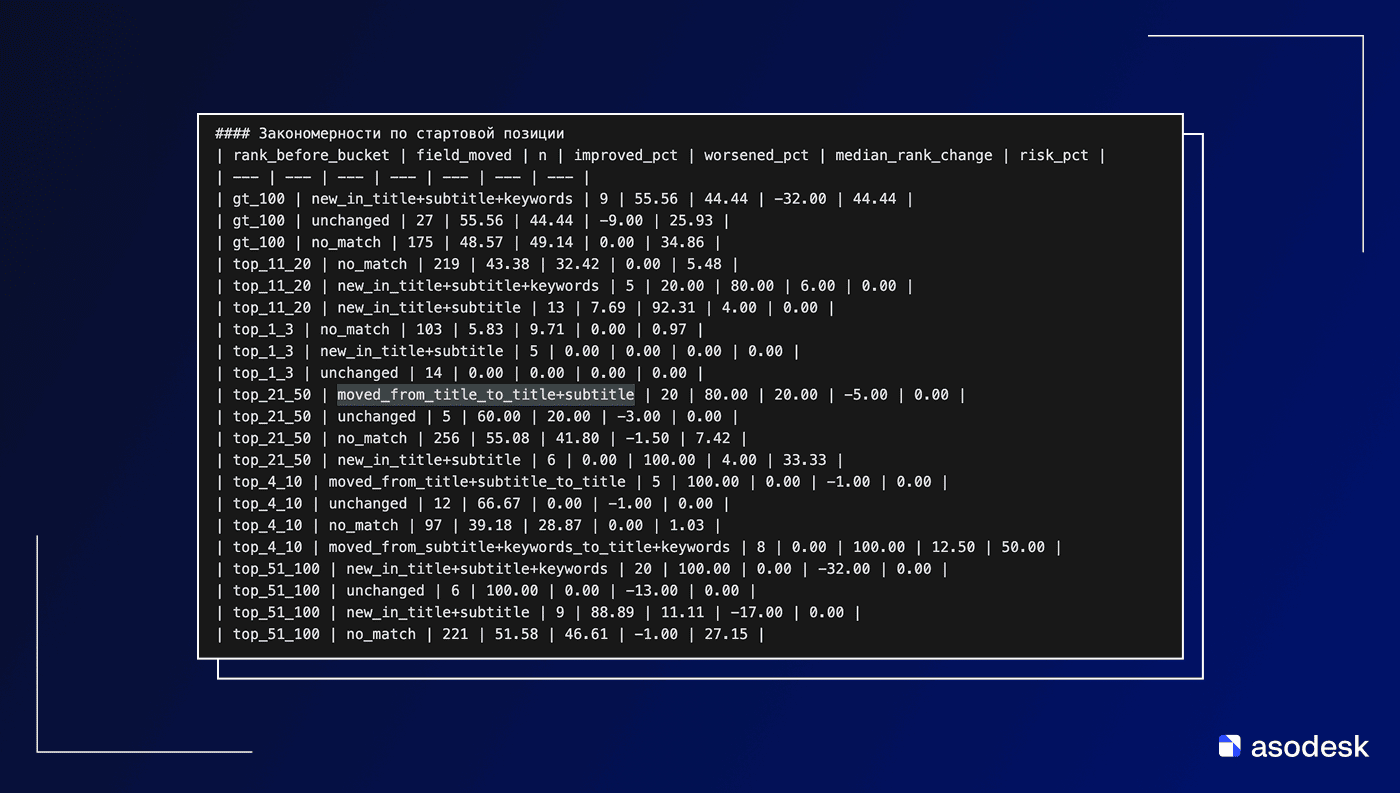
Лучший общий паттерн для App Store – добавление ключевого слова сразу в три поля (title + subtitle + keywords). Странно, но такие данные были получены.
Например, если ключа не было в метаданных, и его новое появление во всех трех полях (new_in_title+subtitle+keywords) фиксировалось в итерации, то улучшение позиции наблюдалось в 76,3% таких случаев при медиане подъема на 30 позиций.
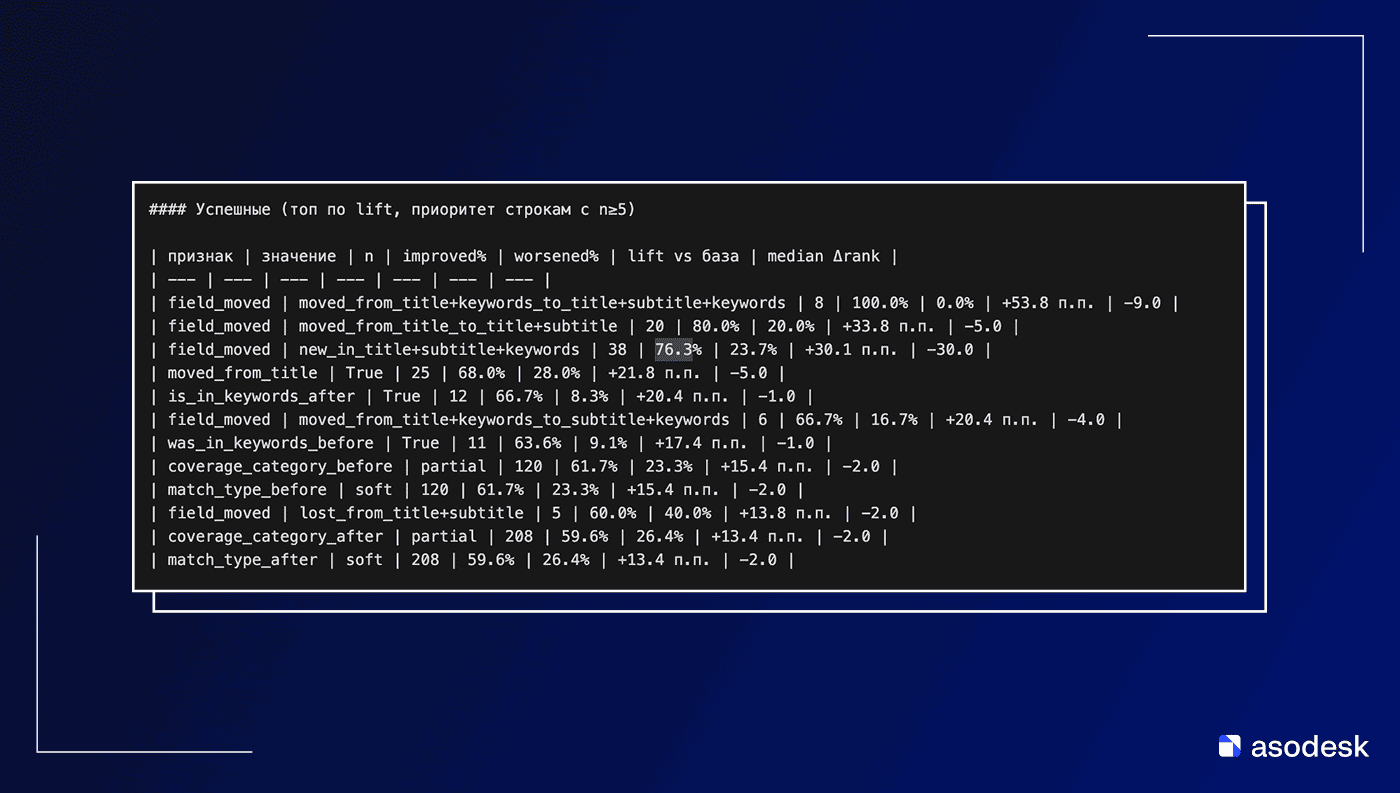
Еще более впечатляющий результат у редкого сценария, когда ключ до изменений был только в Title и Keywords, а после во всех трех полях – во всех 15 случаях из 15 позиция улучшилась (+53,8 п.п.).
В целом расширение присутствия ключа с одного поля на два или три поля коррелировало с повышенным шансом роста: например, перенос ключа из Title в Title+Subtitle (то есть добавление его части в подзаголовок при сохранении части в заголовке) имел 80% улучшений (20/25 случаев).
- Перенос из title в title+subtitle дал 80% улучшений.
- Добавление во все три поля (title+subtitle+keywords) — 76.3%.
- Негативный кейс: перевод из subtitle+keywords в title+keywords дал лишь 33.3%.
Разные сочетания полей работают не одинаково. Например, негативным сценарием в этой выборке оказался перенос ключа из Subtitle + Keywords в Title + Keywords: здесь доля улучшений составила лишь 33,3%, то есть заметно ниже общего уровня по выборке.
На уровне отдельных проектов действительно можно наблюдать случаи, где, например, Title + Keywords выглядит сильнее, чем Title + Subtitle. Но на уровне общей статистики в текущем массиве данных чаще работала обратная картина: комбинации с Subtitle в среднем выглядели устойчивее.
Почему именно так происходит, на текущем этапе ответить нельзя. Для этого нужен больший массив данных и более глубокое разбиение по категориям, типам запросов и другим признакам. Поэтому отдельные кейсы, которые противоречат общей картине, пока корректнее относить к категории частных ASO-сценариев, а не использовать как основание для общих правил.
Точное вхождение ключа не обязательно
Нередко говорят, что без буквального вхождения алгоритмы не увидят запрос. Я писал много раз, что алгоритмы всегда лемматизируют слово, чтобы запрос мог сопоставляться с данными из индекса (“бегать” приводится к лемме “бег”). Это лежит в основе любой поисковой системы.
Это же подтвердили наши данные, что сценарии с частичным мэтчем ключа давали лучшие результаты. Потому что если написать в мете слово “бег”, то оно будет сопоставляться с разными вариациями написания. А вот если в мету добавить “бежать”, не факт, что алгоритм его правильно лемматизирует. И вместо “бег” у нас будет “беж” или что-то в этом роде.
Пример лемматизации русских слов:
- ПлачУ — плач
- Стали — Стать
- Банках — Банк
- Данные — Дать
Интересно, что в App Store в среднем по выборке exact даже не лидирует по доле улучшений. Получается: ключ можно не вписывать дословно, и еще разбить по полям и это работает не хуже, чем точное совпадение в Title. Тяжело с этим согласится, понимаю. И не нужно, так как в данном случае это работает с функциональными словами, а не навигационными и обзорными (классификация ключевых слов согласно патенту Apple).
Например, в самом дальнем сегменте (gt_100) partial заметно лучше exact. С другой стороны, exact в топах (1–3 места) встречался редко, но если встречался – часто был успешен (однако там n слишком мал, чтобы делать выводы).
Partial/soft в большинстве сегментов дали более стабильный результат, и поэтому практический совет, который точно можно вывести – обеспечить хотя бы частичное присутствие ключа, чем не иметь его вовсе. Но когда есть возможность органично внедрить exact (особенно для важных брендовых или высокочастотных запросов) – это дает лучший результат.
Выводы
Выводов не будет. И причина проста: текущего массива данных пока недостаточно, чтобы утверждать, будто выявленные паттерны работают безусловно, одинаково и без исключений. Было бы неверно превращать промежуточные наблюдения в набор универсальных предписаний.
Но это не означает, что полученные результаты не имеют практической ценности. Напротив. Даже на текущем этапе удалось выявить повторяющиеся сигналы не на одном и не на нескольких случайных кейсах, а на существенно большем массиве итераций. А это уже позволяет выходить за пределы частных впечатлений и проводить более содержательные параллели относительно того, как именно могут работать поисковые механизмы сторов (пока они не изменились).
Главный смысл этого анализа не в том, чтобы немедленно сформулировать окончательный свод правил, а в том, чтобы скорректировать само понимание.
Именно поэтому главный итог этой статьи состоит не в перечне советов, а в смене рамки мышления. Если повторяемые сигналы в данных противоречат экспертному фольклору, значит, пересматривать нужно не данные, а сам способ, которым рынок привык объяснять поведение сторов. И это, возможно, более важный результат, чем любая отдельная прикладная рекомендация.









