
Как алгоритмы сторов читают скриншоты (и читают ли)

Нет в ASO‑индустрии столь противоречивой темы, как чтение алгоритмами сторов скриншотов. Кто‑то говорит, что скриншоты читаются, но не может объяснить, зачем и что именно считывается; кто‑то отрицает это, ссылаясь на то, что ни по одному ключу из скриншотов не проиндексировались. Давайте разбираться.
Забегая вперед, отмечу, что не все данные, попадающие в индекс поисковой системы, используются напрямую в функции ранжирования. Часть сигналов может применяться для вспомогательных задач – например, для уточнения семантики приложения, определения его функциональных характеристик или построения тематических моделей. Эти модели, в свою очередь, могут косвенно влиять на ранжирование по ключевым словам, содержащимся в Title, Subtitle и Keywords.
Оглавление
- За и против
- Главный вопрос – зачем алгоритму читать скриншоты?
- Как появился мультимодальный поиск
- Как извлекаются признаки из скриншотов
- Ограничение распознавания текста
- Практические рекомендации по созданию скриншотов
За и против


Но при этом немало экспертов утверждают, что скриншоты могут влиять на поисковую выдачу. Проблема в том, что подтвердить или опровергнуть это на практике крайне сложно. Слишком много переменных в уравнении.
При этом, когда я анализировал источники, меня удивило, насколько много тех, кто считает эту гипотезу правдой. Особенно это заметно в материалах за 2025 год, на фоне обсуждений изменений алгоритмов App Store. Об этом писали Appfigures, ARPU Brothers, 36Kr, ScreenshotWhale, App Guardians, Strataigize и многие другие.
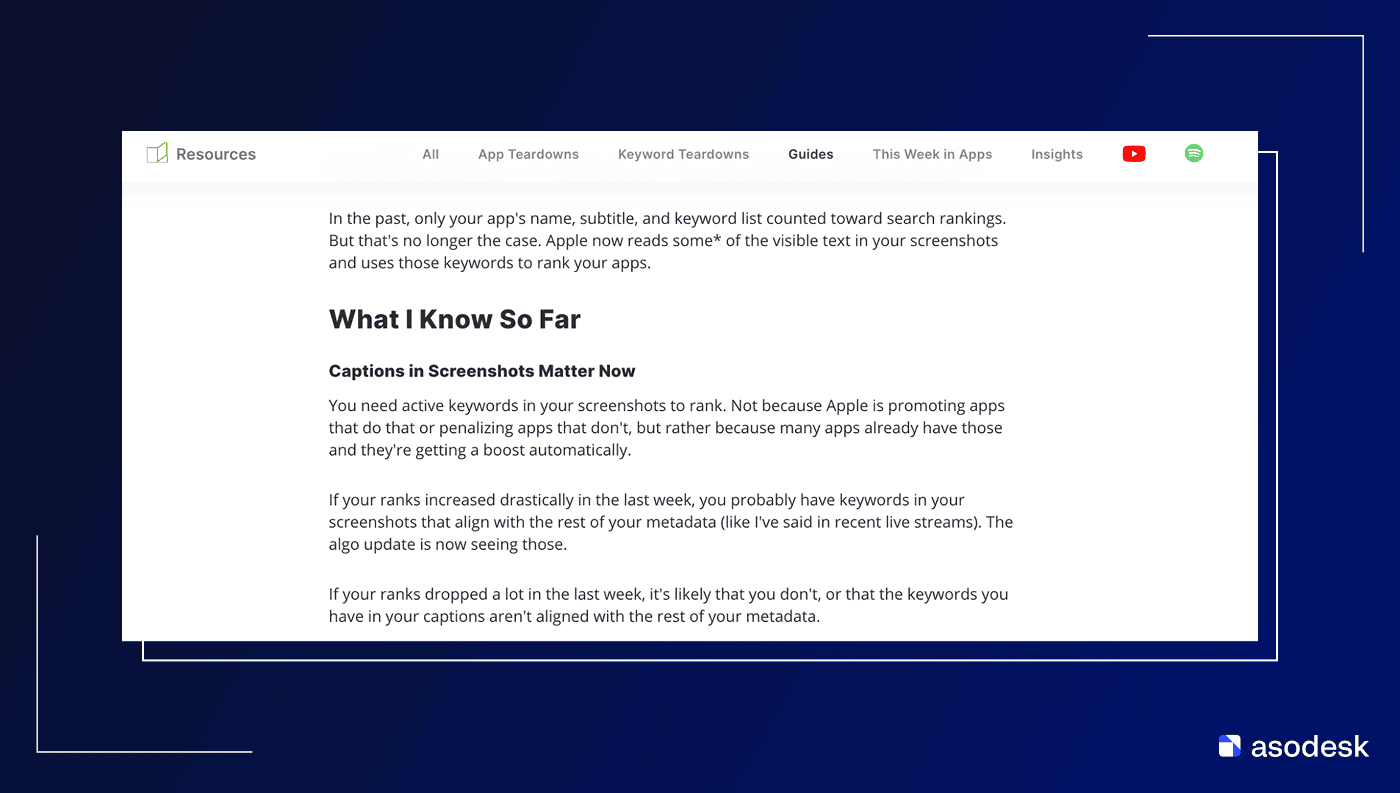

Рассмотрим пример, которым поделился стажер Asodesk-академии. Если в поиске App Store ввести один символ, например @ или #, в выдаче появляются приложения, где эти символы присутствуют на иконках или в визуальных элементах интерфейса.

Или вот пример. Посмотрите на иконку второго приложения:
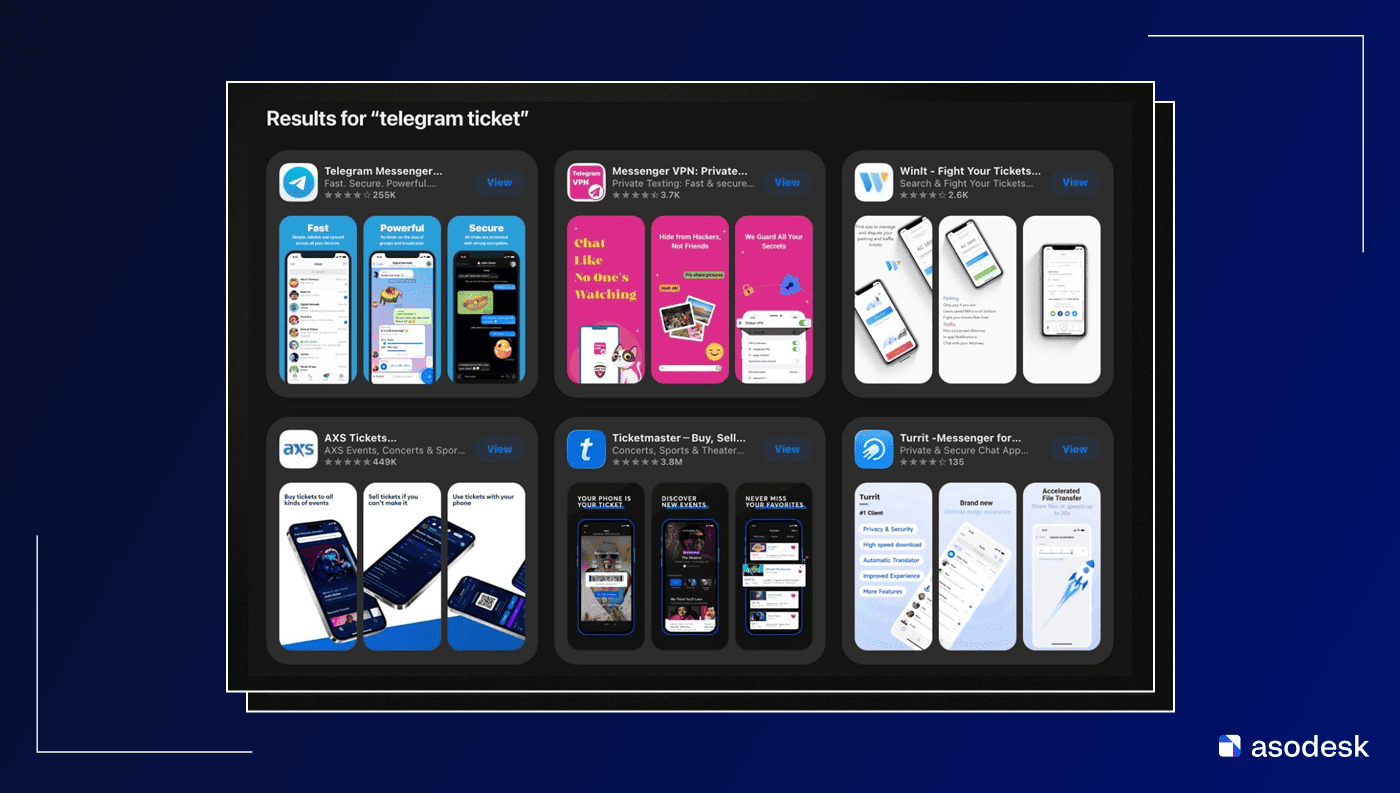
На первый взгляд может показаться, что алгоритм действительно считывает визуальные элементы изображений. Однако даже такой результат нельзя считать однозначным доказательством.
С одной стороны, это может быть результатом анализа изображений – например, распознавания символов на иконках или скриншотах с помощью OCR.
С другой стороны, возможны и более простые объяснения. Поисковая система может автоматически расширять запрос, чтобы повысить полноту выдачи. Например, символ @ может интерпретироваться как маркер коммуникации или социальных сервисов, поэтому в результатах появляются почтовые клиенты и мессенджеры.
Этот пример лишь показывает, что современные поисковые системы используют дополнительные механизмы интерпретации запросов, которые могут включать как анализ визуальных сигналов, так и различные формы семантического расширения запроса. А не просто вставил ключ – жди позиции, не вставил – позиций не будет. Иногда навставляешь – а позиций все равно нет, не так ли?
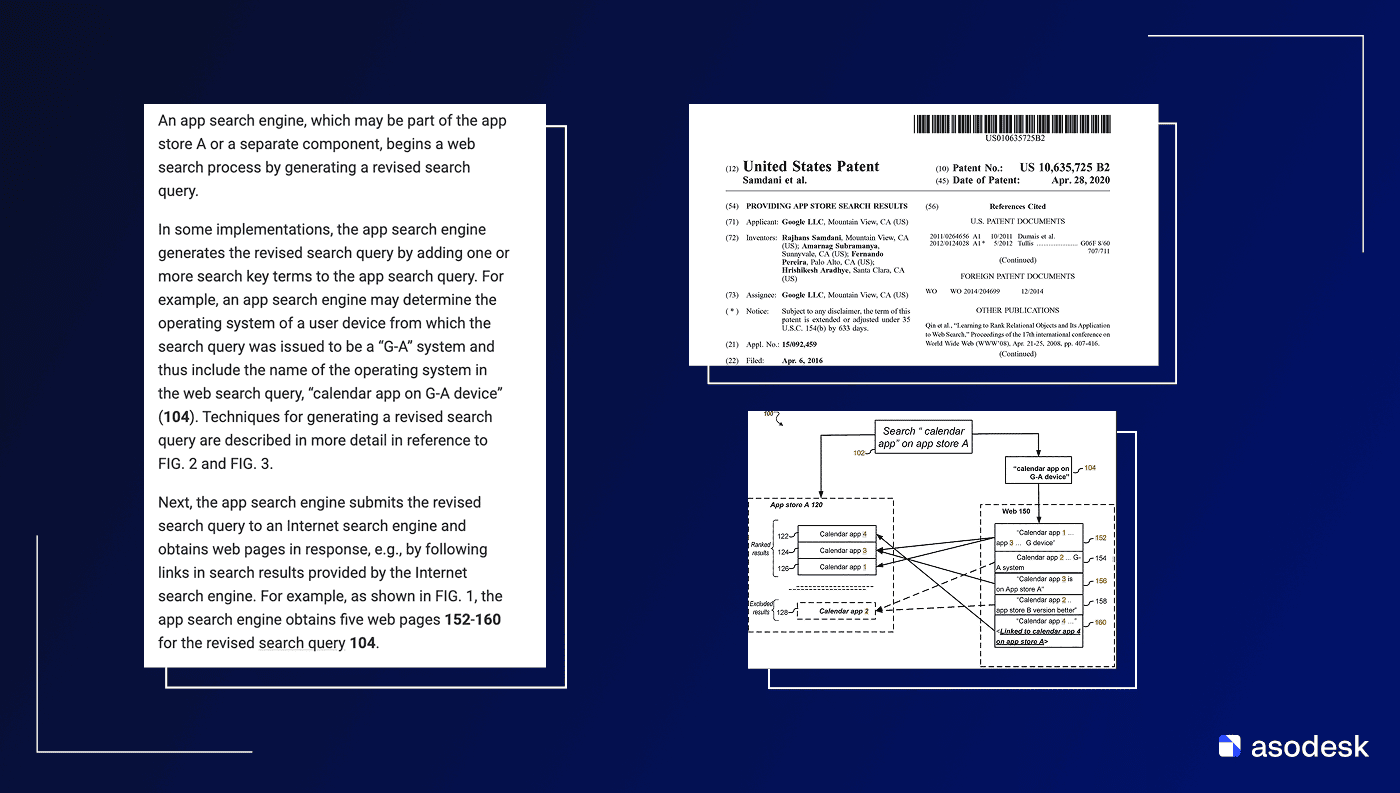
Предлагаю просто посмотреть на последнюю патентную заявку Apple. (На момент написания статьи эта заявка находится на рассмотрении патентного ведомства.)
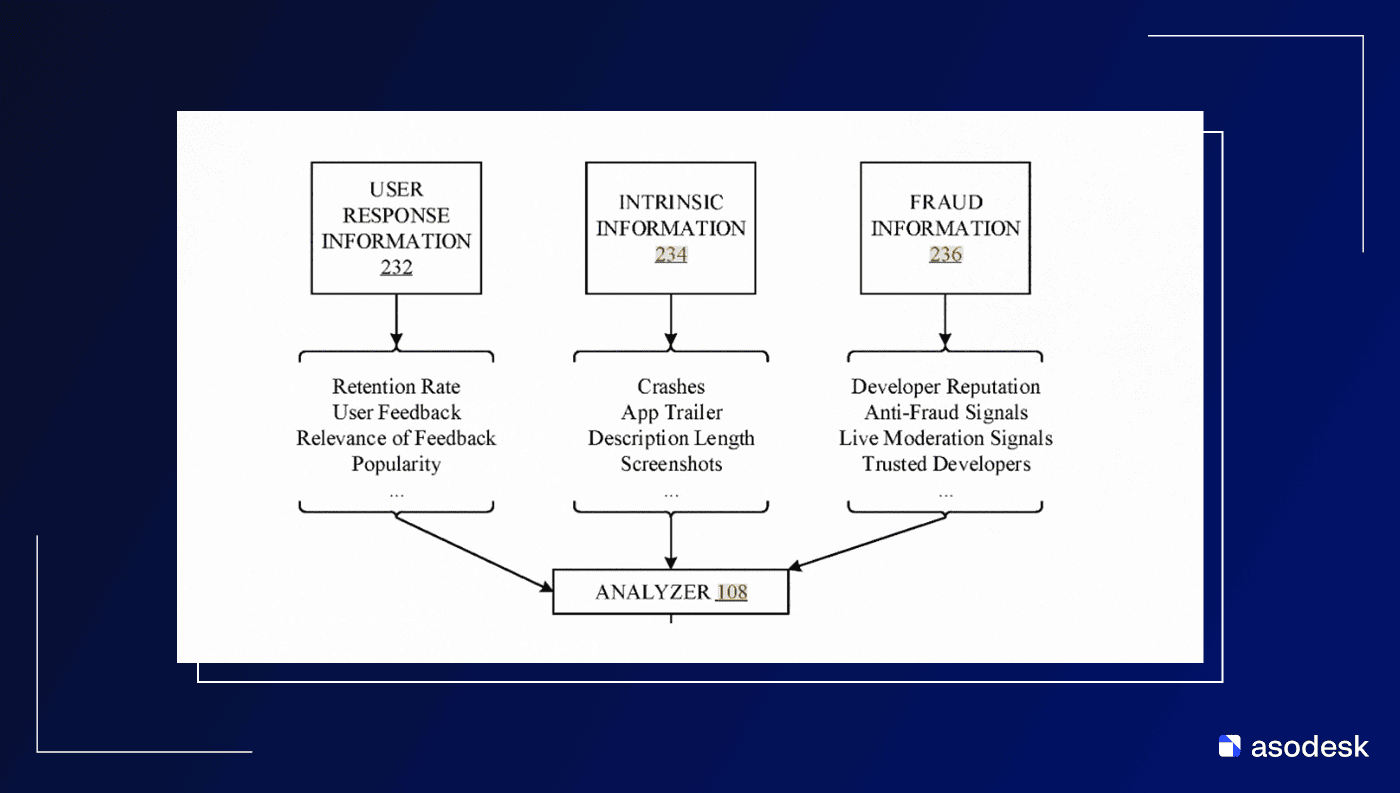
В общих чертах описан процесс: формируется профиль пользователя – что он скачивает, что покупает, на что кликает, какие отзывы оставляет – и профиль приложения – поведенческие и продуктовые характеристики, метаданные и многое другое.
Что любопытно, алгоритм также анализирует трейлер приложения, длину описания и скриншоты. А может просто фиксирует данные, например, есть трейлер – значит есть полная информация, поднимем-ка его выше. Без всякой магии.
Все эти профили поступают в анализатор. При запросе профиль пользователя сопоставляется с профилями приложений в пространстве векторов, и далее происходит ранжирование в зависимости от близости.
Именно в этой заявке есть и подтверждение того, что поиск в App Store также расширяет поисковый запрос пользователя, исходя из профиля пользователя (например, для пользователя-геймера автоматически в запрос добавляется ключ game).
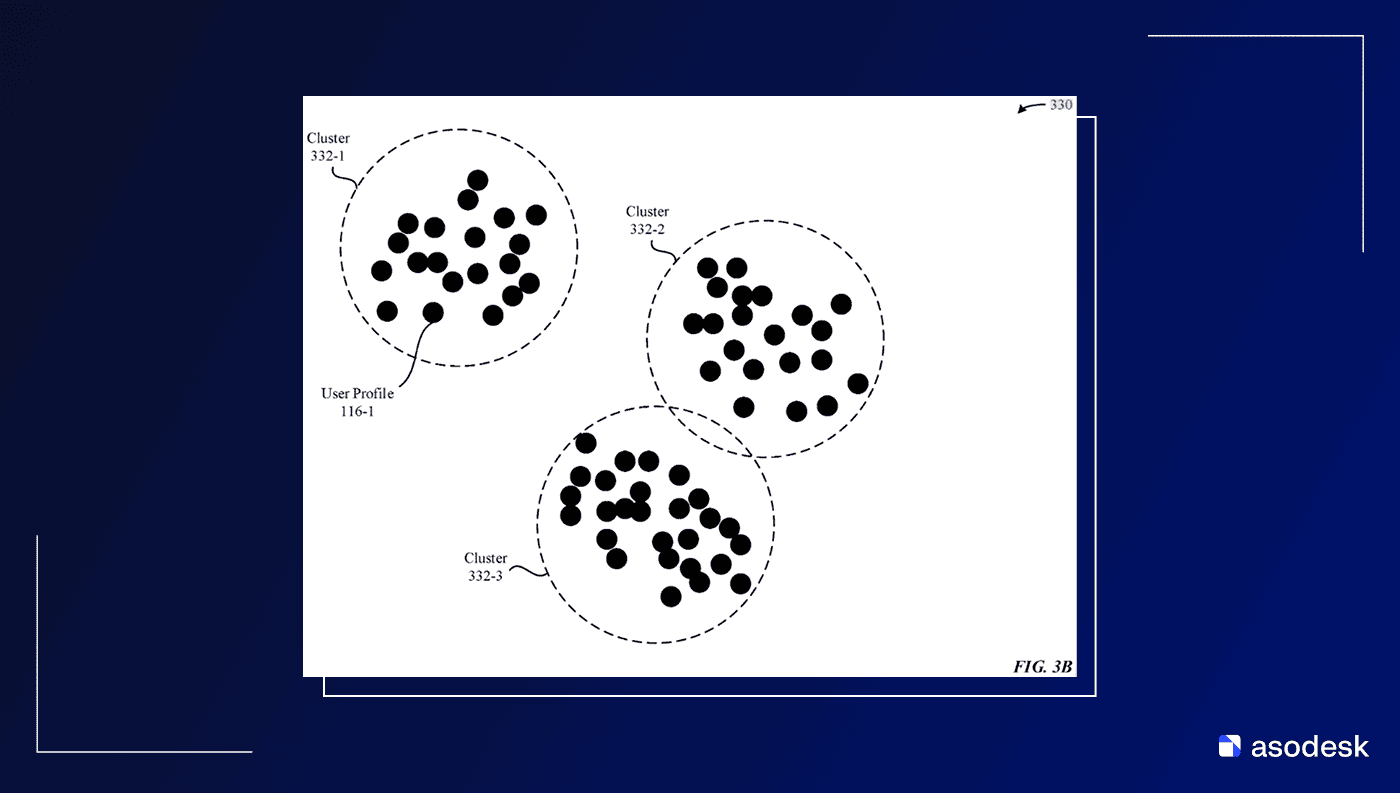
Именно так сейчас работает персонализированная выдача на главных экранах (в поиске это еще не применяется, но это только пока).
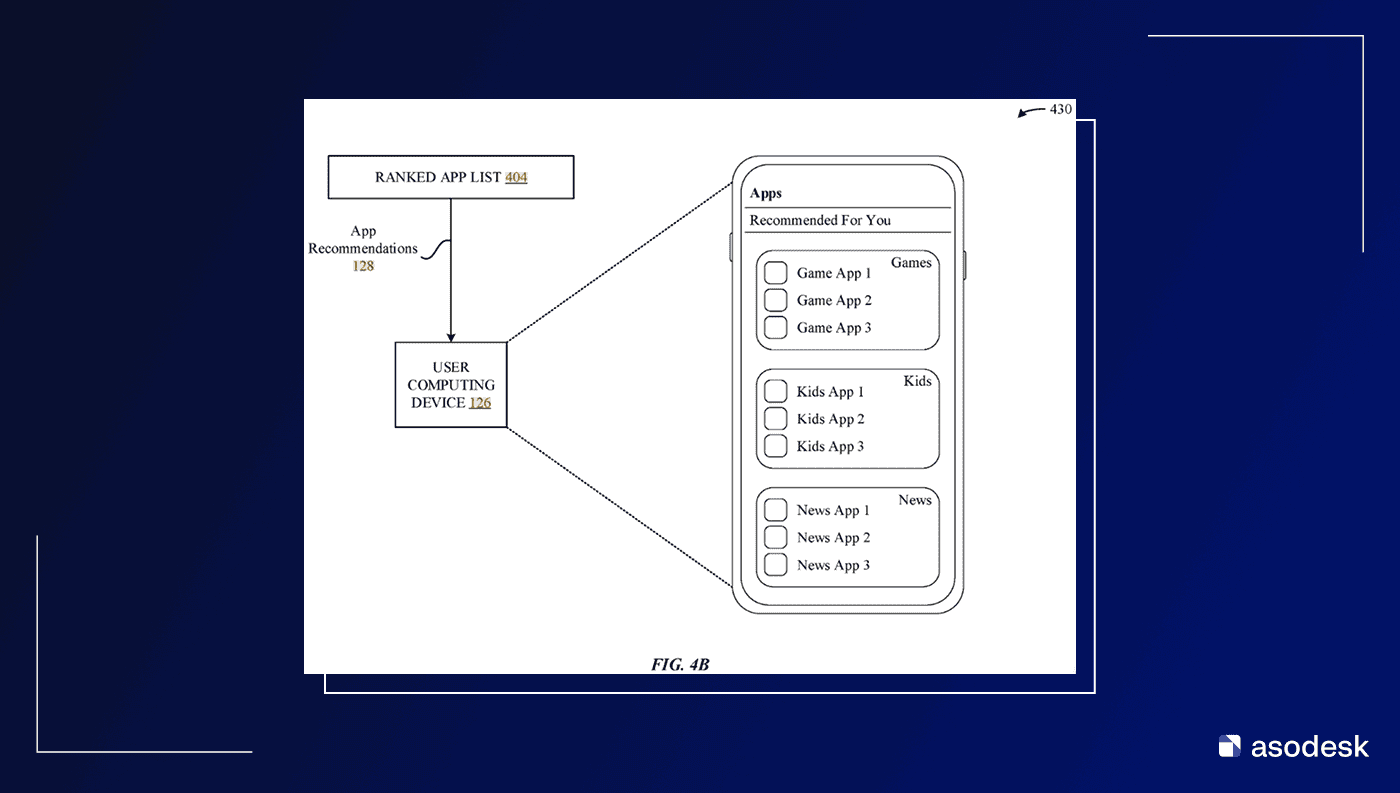
В открытых источниках Apple прямо пишет: «В некоторых случаях предлагаемые поисковые запросы могут быть персонализированы в разделе Discover, а приложения персонализированы в разделе Suggested на основе вашей предыдущей активности в App Store».

Пример, как это работает:
Очевидно, что на этом развитие не остановится: у Apple регулярно появляются вакансии, связанные с персонализацией поиска и рекомендательных систем.

Есть и другая вакансия, связанная с Apple Ads.
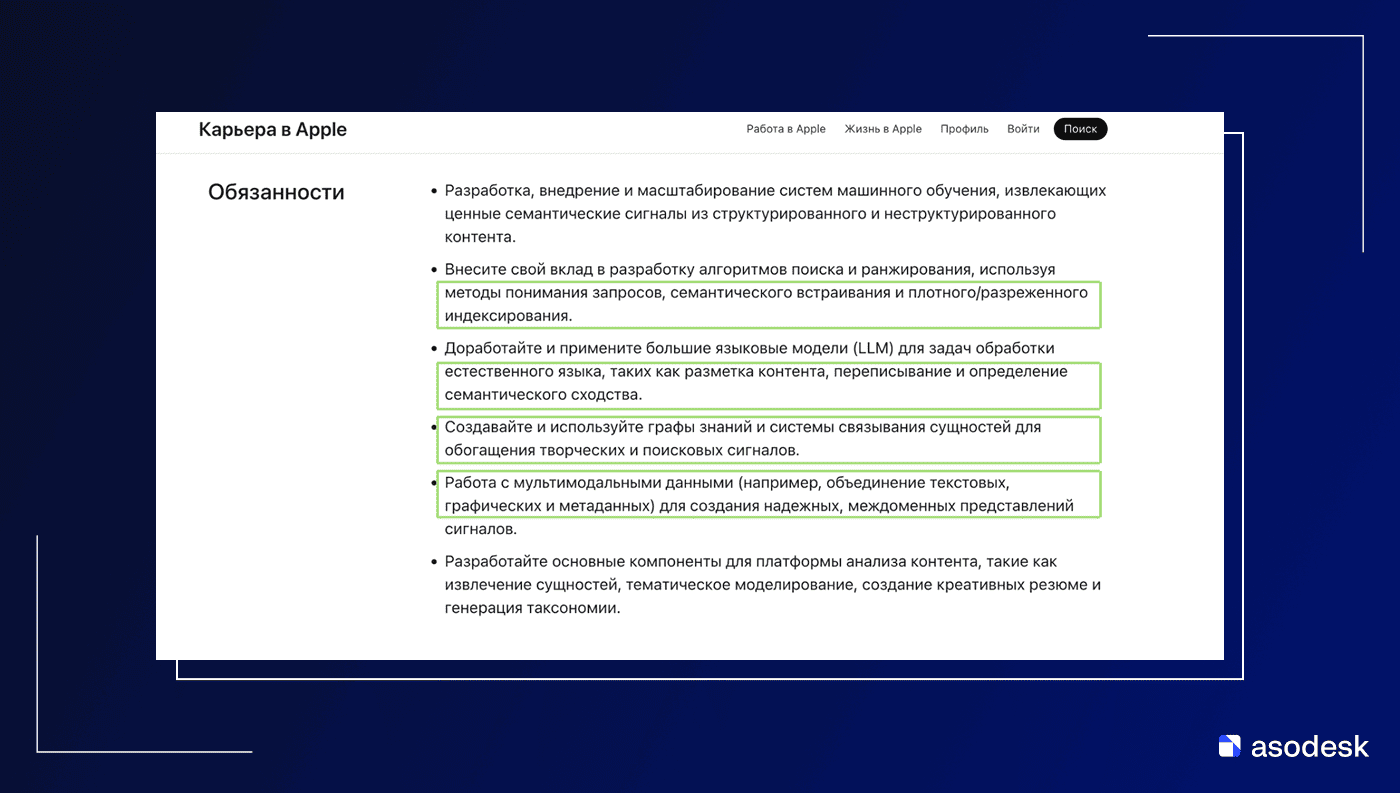
Обратите внимание на «работа с мультимодальными данными». Это есть ни что иное, как реализация мультимодального поиска, когда текстовые и графические метаданные объединяются для формирования единого профиля.
По своей сути работа с мультимодальными данными неотделима от персонализированного поиска. Именно обогащенные данные помогают лучше персонализировать выдачу.
Лично я в своей практике таким никогда не занимался. Отдельно проходил курсы от зарубежных экспертов, но на практике реализовывать пока желания нет.
Но как именно они комбинируются? И самое главное – что считывается со скриншотов и как это в конечном счете влияет на ранжирование? Это мы разбираем в новой статье про ASO Engineering.

Студенты первого потока курса ASO Engineering для специалистов уровня Middle+ очень хотели, чтобы появился урок по работе с визуалами. Он действительно будет, а пока, чтобы не затягивать ожидание, кратко расскажу о процессе чтения и о том, как правильно готовить скриншоты, чтобы алгоритм мог их корректно интерпретировать. А урок посвятим уже практической работе над вашими приложениями.
Главный вопрос – зачем алгоритму читать скриншоты?
Чаще всего дополнительные данные используются для построения тематического профиля приложения и для проверки соответствия заявленному функционалу. Такой подход с одной стороны помогает улучшать качество ранжирования, с другой – бороться с теми, кто обходит санкции.
Если алгоритм не может распознать текст на скриншотах, он вынужден опираться только на привычные метаданные, в которых есть только ключи, но никакого контекста. Это снижает шанс попасть в точную тематическую группу. А у нас оба стора заявили о поиске на естественном языке. И при таком поиске алгоритм не может ограничиваться только тем, что мы всегда оптимизируем.
На самом деле факторов очень много, но я упрощаю до безумия, так как знаю, что вы все равно это не читаете – вам нужны практические волшебные таблетки “что и как делать”, но, увы, так это не работает. Нужно понимать, как работают алгоритмы, а не слепо доверять ASO-хакам.
Даже при идеальном дизайне не стоит ожидать резкого роста позиций только за счет текста на изображениях. Но игнорирование этих требований гарантировано может ухудшать качество ранжирования.
То есть: правильно оформленные изображения повышают доверие алгоритма к вашему приложению и увеличивают вероятность, что оно будет показано по релевантным запросам.
Но, опять же, на данный момент у нас нет оснований ни подтверждать, ни исключать влияние скриншотов на формирование выдачи.
Как появился мультимодальный поиск
Любая поисковая система начинается со сбора и подготовки данных. У каждого стора свои данные. Ведь не все помогает улучшать ранжирование. Иногда лишняя информация ухудшает результаты.
Я об этом пишу практически в каждой статье, но это очень важно объяснить. Специалист, который не понимает, как устроены поисковые системы, не сможет эффективно работать. Для него, например, «выпасть из индексации» оказывается равносильно «выпасть из ранжирования», хотя на практике это разные процессы.
После этого создается индекс. Классический обратный индекс (инвертированный) сопоставляет каждому терму список документов, где он встречается. Он обеспечивает эффективный поиск по ключевым словам. Без такого поиска, поиск, например, по брендовым названиям существовать не может.
Но современные поисковики используют также векторные индексы, позволяющие хранить эмбеддинги документов и запросов и быстро находить близкие элементы по косинусному расстоянию или евклидову.
В качестве структур данных для быстрого поиска по векторному пространству применяются графы приближенного ближайшего соседа (HNSW) и другие структуры.
Когда пользователь вводит запрос, система должна правильно его интерпретировать. Этот этап включает нормализацию (приведение слов к нижнему регистру, удаление стоп-слов, лемматизацию), токенизацию и распознавание сущностей (NER).
Важным компонентом является классификация намерения пользователя и определение языка запроса. Точнее, изначально идет определение языка, а потом все остальное. Ведь, чтобы лемматизировать слова (привести к именительному падежу единственного числа), нужно знать, какой это язык. Ведь разные языки – разные правила. Задайтесь вопросом: а когда микс языков, то как это работает? 🙂
В еще одном патенте Apple описывает этот процесс так:
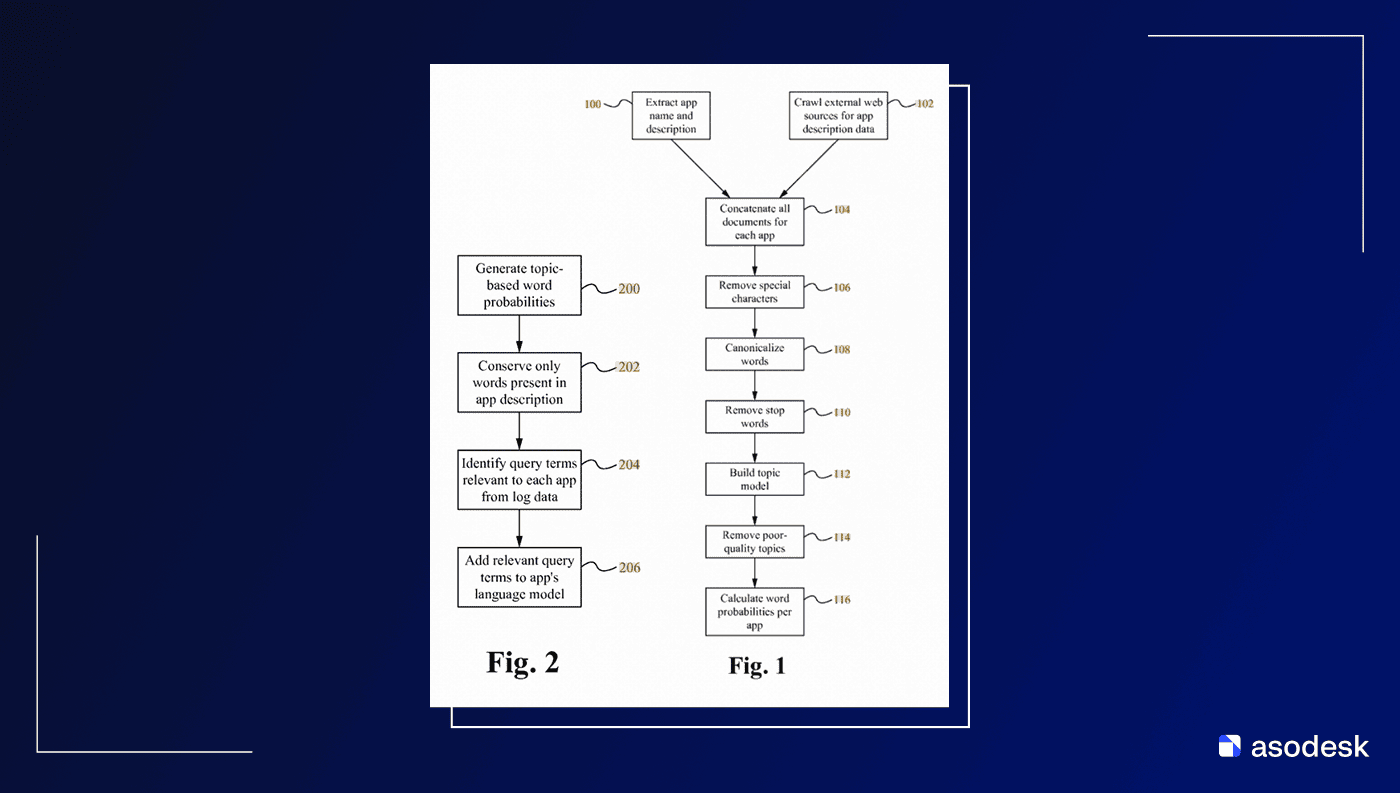
После нормализации формируется набор кандидатов. Для повышения охвата комбинируются разреженные модели и плотные.
Посмотрите еще раз на скриншоты вакансий. По сути все это Apple записывает в минимальные требования к знаниям кандидатов. Не удивительно – это индустриальный подход в проектировании поисковых систем.

Изначально разработчики поисковых систем пытались явно формализовать правила релевантности, но практика показала:
- объем данных увеличивается;
- документы постоянно меняются;
- информация разнородна.
Поэтому универсальный набор правил ранжирования просто не может существовать.
Были разработаны специальные модели, а потом в нашу сферу проникло глубокое обучение, машинное обучение, трансформеры и генеративные модели. И после появления нейронных моделей архитектура поиска очень сильно изменилась. Учитывая, что объем информации увеличивается с очень высокой скоростью и выделить из всего мусора реально релевантные результаты даже современными методами становится сложно.
Поэтому поисковые системы постепенно стали переходить к мультимодальным архитектурам, где документы описываются не только текстовыми признаками, но и визуальными представлениями.
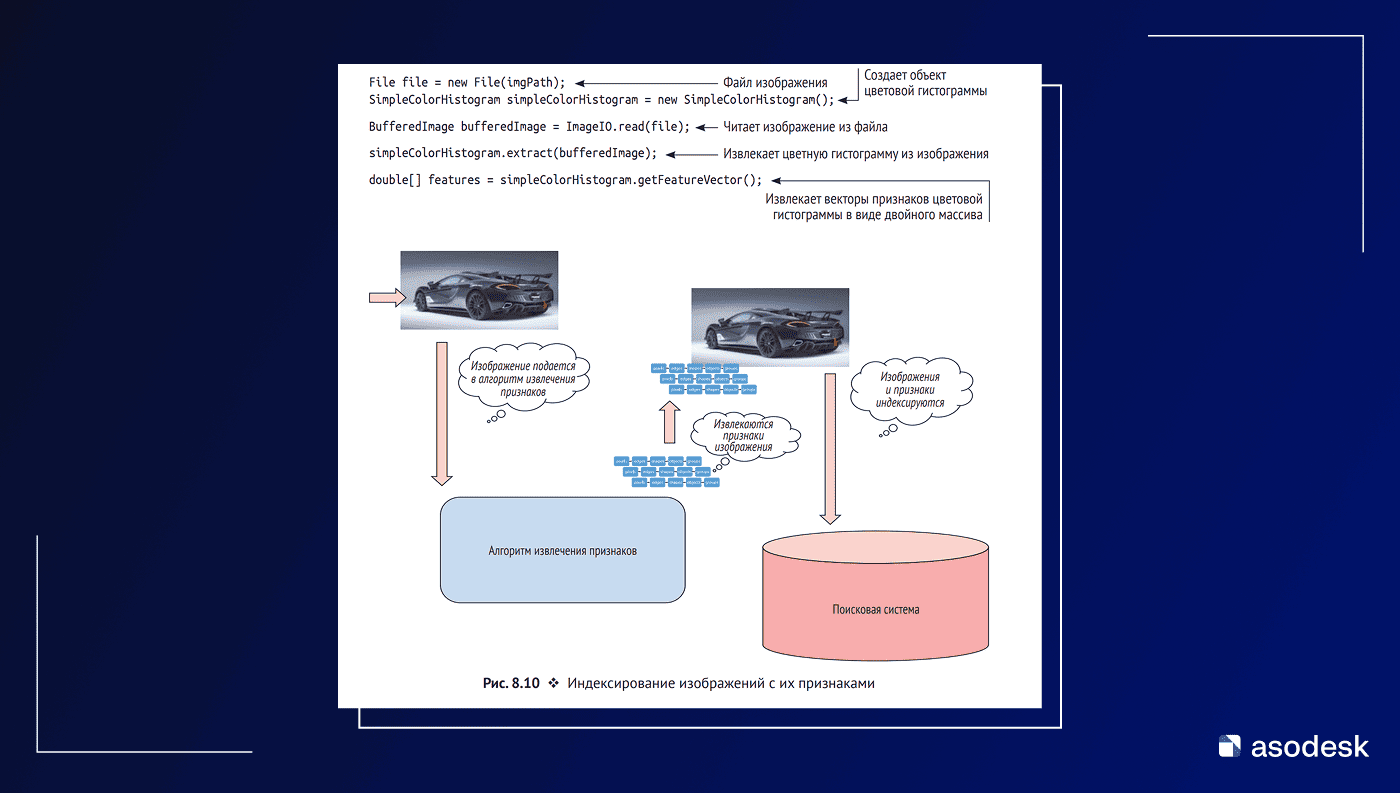
В таких системах изображение сначала преобразуется в набор признаков с помощью сверточных нейронных сетей (CNN), после чего строится его векторное представление.
Затем эти векторы можно индексировать и искать по ним так же, как по текстовым документам.
Другими словами, изображение превращается в такой же объект поиска, как и текст.
Как извлекаются признаки из скриншотов
Пайплайн для таких задач обычно состоит из двух частей.
1. OCR слой
Сначала из изображения извлекается текст:
- детекция текстовых областей;
- сегментация строк;
- распознавание символов.
Этот текст добавляется в семантический профиль приложения.
2. Визуальные признаки интерфейса
Параллельно извлекаются визуальные признаки UI:
- кнопки;
- иконки;
- слои интерфейса;
- тип приложения.
Далее текстовые и визуальные признаки объединяются.
Есть несколько архитектур:
- Early fusion – признаки разных модальностей объединяются на раннем этапе (например, через конкатенацию векторов);
- Late fusion – текст и изображения оцениваются отдельно, а их оценки объединяются на финальном этапе;
- Joint embedding – текстовые и визуальные данные проецируются в общее векторное пространство и сопоставляются напрямую.
Затем пользователь вводит запрос, и система ищет ближайшие приложения в векторном пространстве. Если признаки, извлеченные из скриншотов, согласуются с текстовой информацией приложения, они могут усиливать его семантическое представление при сопоставлении с запросом.
Как я писал выше, добавить ключ на скриншот и ждать позиций, особенно, если этот ключ семантически не релевантен приложению, смысла нет.
Но тексты на визуалах могут влиять на:
- Семантическую классификацию приложения;
- Классификацию функциональности;
- Персонализированные рекомендации;
- Ранжирование в мультимодальной модели.
Но, работает ли это сейчас? К сожалению, даже сотнями экспериментами проверить не получится. Архитектура поисковых систем очень сложная. Но, то что в ближайшем будущем такой подход станет самым логичным – это факт. Вот только заметим мы это или нет?

Ограничение распознавания текста
Есть ряд факторов, которые усложняют распознавание:
- Низкое качество изображений или добавленный шум снижают точность распознавания;
- Слабый контраст между текстом и фоном резко ухудшают качество OCR. Минимальный рекомендуемый уровень контрастности по стандартам доступности: WCAG ≥ 4.5:1;
- Проблемы также вызывают: блики, тени, загрязнения, различные пятна для красивого дизайна;
- Декоративные и рукописные шрифты распознаются значительно хуже стандартных;
- На точность OCR также влияют: JPEG-артефакты, размытия, гамма-искажения, текстуры и узоры фона;
- Особенно проблемным является слияние текста и фона, когда символы теряются в паттернах изображения;
- Детекцию текстовых областей усложняют: текст под углом, перспективные искажения, текст на изогнутых поверхностях, частично перекрытые символы.
Практические рекомендации по созданию скриншотов
Теперь, когда понятно “как это работает” и “почему не работает”, составим список рекомендаций “чтобы заработало”. Даже если мультимодальная обработка данных сейчас не используется, такой подход не ухудшит дизайн, а в ряде случаев даже улучшит его, поскольку пользователю будет проще воспринимать информацию.
1. Используйте достаточное разрешение
Скриншоты должны быть четкими и не содержать размытий. Разрешение 72 dpi, традиционно используемое для веб-графики, недостаточно для корректного распознавания текста. Рекомендуется использовать изображения с разрешением 300 dpi и выше, чтобы алгоритмы компьютерного зрения могли корректно выделять текст и интерфейсные элементы.
2. Обеспечьте высокий контраст
Текст и ключевые элементы интерфейса должны четко выделяться на фоне и не сливаться с изображением. Рекомендуется соблюдать коэффициент контрастности ≥ 4.5:1. Это повышает вероятность корректного распознавания текста и интерфейсных элементов. Проверить контрастность можно по ссылке.
3. Выбирайте правильные шрифты
Для подписей лучше использовать простые шрифты (гротески):
- Arial;
- Tahoma;
- Helvetica;
- Roboto.
Такие шрифты обеспечивают хорошую читаемость и легко воспринимаются на небольших экранах. Хотя они могут казаться слишком простыми с дизайнерской точки зрения, их использование оправдано: в интерфейсах и маркетинговых материалах ключевая задача – быстрое и однозначное считывание сообщения пользователем. Это и отличает правильный дизайн от красивого.
Рекомендации:
- избегать курсива;
- избегать декоративных шрифтов;
- текст должен располагаться горизонтально.

4. Оставляйте поля
Элементы интерфейса не должны примыкать к краям изображения.
Рекомендуется:
- использовать равномерные отступы;
- оставлять поля вокруг текста и UI-элементов.
Это помогает алгоритмам компьютерного зрения корректно сегментировать изображение и выделять текстовые блоки.
5. Минимизируйте визуальный шум
Сложные фоны ухудшают распознавание текста.
По возможности следует удалить:
- декоративные узоры;
- сложные градиенты;
- лишние графические элементы.
Чем чище фон, тем легче алгоритмам.
6. Балансируйте яркость
Избегайте:
- пересвеченных областей;
- слишком темных участков.
Оптимальная экспозиция позволяет сохранить детали интерфейса и повышает качество распознавания текста.
7. Добавляйте ключевую информацию
Скриншоты должны содержать короткие и информативные подписи, передающие основные преимущества приложения.
Желательно, чтобы текст на изображении включал ключевые слова, описывающие функциональность приложения. Такие слова могут быть извлечены алгоритмами компьютерного зрения и использованы для построения семантического профиля приложения.
8. Тестируйте OCR перед публикацией
Перед загрузкой скриншотов в стор рекомендуется проверить, как они распознаются системами OCR.
Для этого можно использовать:
- Google Vision OCR;
- Tesseract;
- Azure Computer Vision.
Если система распознает текст с ошибками, скриншоты лучше скорректировать до публикации.
9. Учитывайте особенности видео и трейлеров
Видео также может анализироваться автоматически. По сути, это та же последовательность изображений, только в большем объеме.
Рекомендации:
- избегать слишком быстрых переходов;
- не использовать анимации, размывающие текст;
- уделить особое внимание первым секундам видео;
- добавить понятный заголовок;
- использовать субтитры.
10. Локализуйте с умом
Создавайте отдельные наборы скриншотов для разных языков и регионов. Не машинный перевод текущих скриншотов, а тексты под вашу целевую аудиторию на естественном языке носителей.
Алгоритмы персонализации учитывают языковые предпочтения пользователей, поэтому скриншоты с локализованным текстом могут повышать релевантность приложения для соответствующих поисковых запросов.
Следование этим рекомендациям не гарантирует мгновенного попадания приложения в топ выдачи. Однако оно значительно повышает вероятность того, что алгоритмы корректно распознают содержимое скриншотов и оценят его релевантность пользовательским запросам.
Что в итоге
Скриншоты в магазинах приложений могут анализироваться алгоритмами, но их роль отличается от классических текстовых метаданных. Они, скорее всего, не используются как прямой источник ключевых слов для ранжирования (данных мало, а факторов много чтобы заявлять об этом). Вместо этого информация из изображений применяется для уточнения семантики приложения, его классификации и формирования тематического профиля.
При этом возможности компьютерного зрения остаются ограниченными. Контраст текста, читаемость шрифтов, размер надписей, отсутствие визуального шума и корректная композиция изображения напрямую влияют на качество распознавания. Если алгоритм не может корректно извлечь информацию из скриншота, этот сигнал просто не будет использован.
Поэтому задача – не просто сделать визуально привлекательные изображения, а подготовить их так, чтобы они были понятны и пользователю, и алгоритмам. А текст работал не с позиции ASO, а грамотного маркетинга.










