
Почему ваши семантические ядра не являются семантическими

Содержание
- Что дал анализ сотни итераций за 2020-2025 годы
- Что не так с семантическими ядрами
- Ключевые идеи о том, как работает поиск
- Семантические ядра в век векторного поиска
- Как собрать семантическое ядро в векторном пространстве
Что вообще означает «семантическое ядро»? Многие ASO-специалисты по привычке называют семантическим ядром просто список ключевых слов для продвижения приложения. Обычно такой список собирают, опираясь на частотность запросов, подсказки поиска и аналитику конкурентов. Затем эти слова напрямую добавляют в метаданные приложения. Предполагается, что чем больше популярных слов точь-в-точь указано, тем лучше приложение будет ранжироваться. Но так ли это?
Саммари статьи
В статье разбирается, почему привычные «семантические ядра» в ASO часто являются просто списками популярных ключей, а не отражением реальной смысловой структуры запросов. Такой подход вырос из логики лексического поиска. Но практика и изменения в архитектуре поиска показывают, что этого уже недостаточно.
Анализ сотен итераций 2020–2025 годов показывает, что текстовые правки все чаще дают эффект расширения охвата (позиции 21–50 и 51–100), а не стабильные росты в топе. Проблема усугубляется тем, что даже более продвинутые ядра все равно остаются «лексическими»: они не показывают дубли по смыслу, не отделяют разные сценарии использования и не дают объективной картины. Решения по приоритетам часто остаются субъективными.
Далее объясняется переход индустрии к поиску по смыслу и гибридным моделям, где лексический слой отбирает кандидатов, а семантика и поведенческие сигналы уточняют ранжирование. На этом фоне простое «набивание» метаданных синонимами и околорелевантными ключами может ухудшать позиции: вектор описания размывается между темами. Правильнее сохранять чистоту смысловых групп и раскрывать их связно.
В финале дана практическая методика построения действительно семантического ядра в векторном пространстве: собрать широкий пул запросов, получить эмбеддинги, построить граф близости, кластеризовать, приоритизировать кластеры по потенциалу, отобрать формулировки под интенты и визуализировать покрытие. Такое ядро становится не только инструментом ASO, но и источником продуктовых инсайтов.
В итоге читатель сможет составить самостоятельно два отображения семантического ядра:

Что дал анализ сотни итераций за 2020-2025 годы
Традиционный подход в ASO фокусировался на буквальном совпадении слов. По сути, семантическое ядро для нас стало набором отдельных поисковых запросов, которые распределяются по частотности и добавляются в мету. Через 2-4 недели идет анализ влияние этой меты на позиции приложения по этим ключам. Делается следующая итерация. Далее – бесконечный цикл.
Недавно я начал строить прогностическую аналитику на основе машинного обучения, чтобы заранее оценивать, какой прирост видимости и конверсии дадут те или иные текстовые итерации. В качестве базы для модели были взяты сотни отчетов итераций наших, клиентов и коллег по цеху за 2020–2025 годы: что было в метаданных, что изменили, какой получили результат, использовались ли мотивированный трафик, реклама и другие факторы. То есть почти идеальный массив данных для анализа.
К 2025 году в динамике стало ясно, что текстовые итерации уже не работают так хорошо, как в 2020 году и в первую очередь увеличивают количество индексируемых запросов в диапазонах позиций 21–50 и 51–100. Сдвиги в верхних бакетах (топ-1 и топ-2–5) на 1–3 позиции происходят значительно реже и зависят не только от текстовых итераций.
Основной эффект таких итераций — расширение охвата, а не быстрый рост установок. При этом 70–90% органического трафика обычно дают 5–15 ключей. Потеря даже одного сильного запроса заметно просаживает установки.
А главное — все эти бесконечные танцы с ключами сами по себе не выполняют функции, которую от них ожидают. И проблема напрямую лежит в семантических ядрах. Давайте разберемся, что с ними не так.
Что не так с семантическими ядрами
Вот типичное семантическое ядро образца 2021 года:
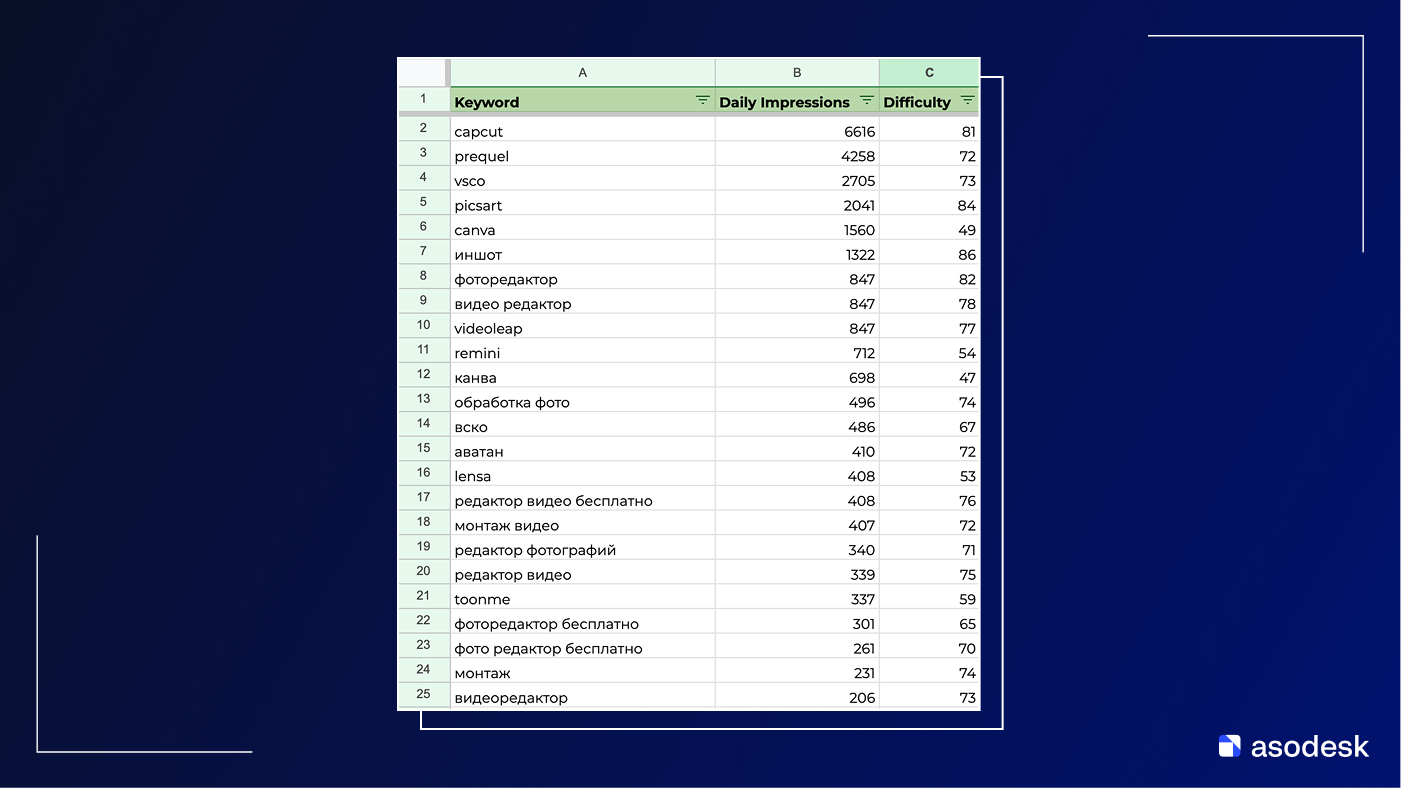
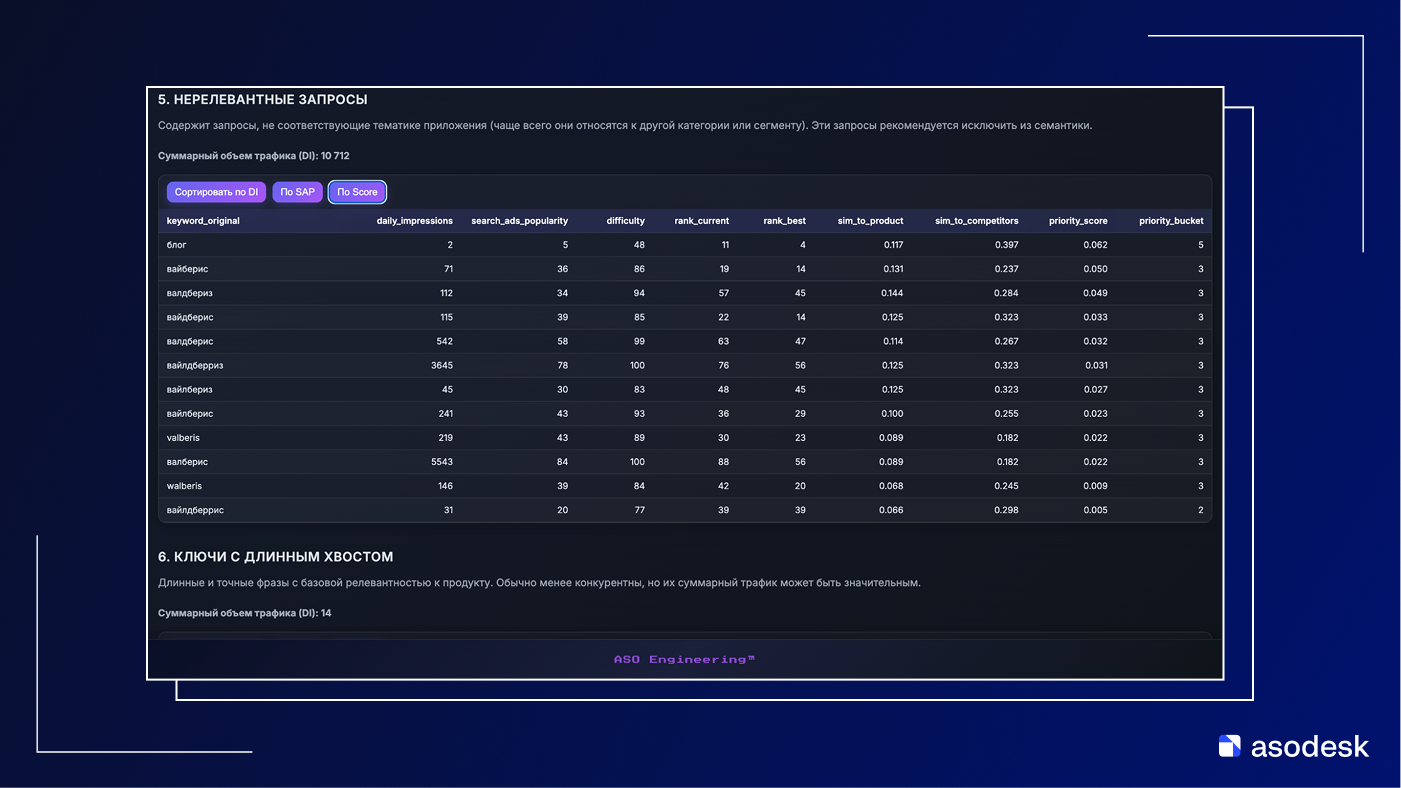
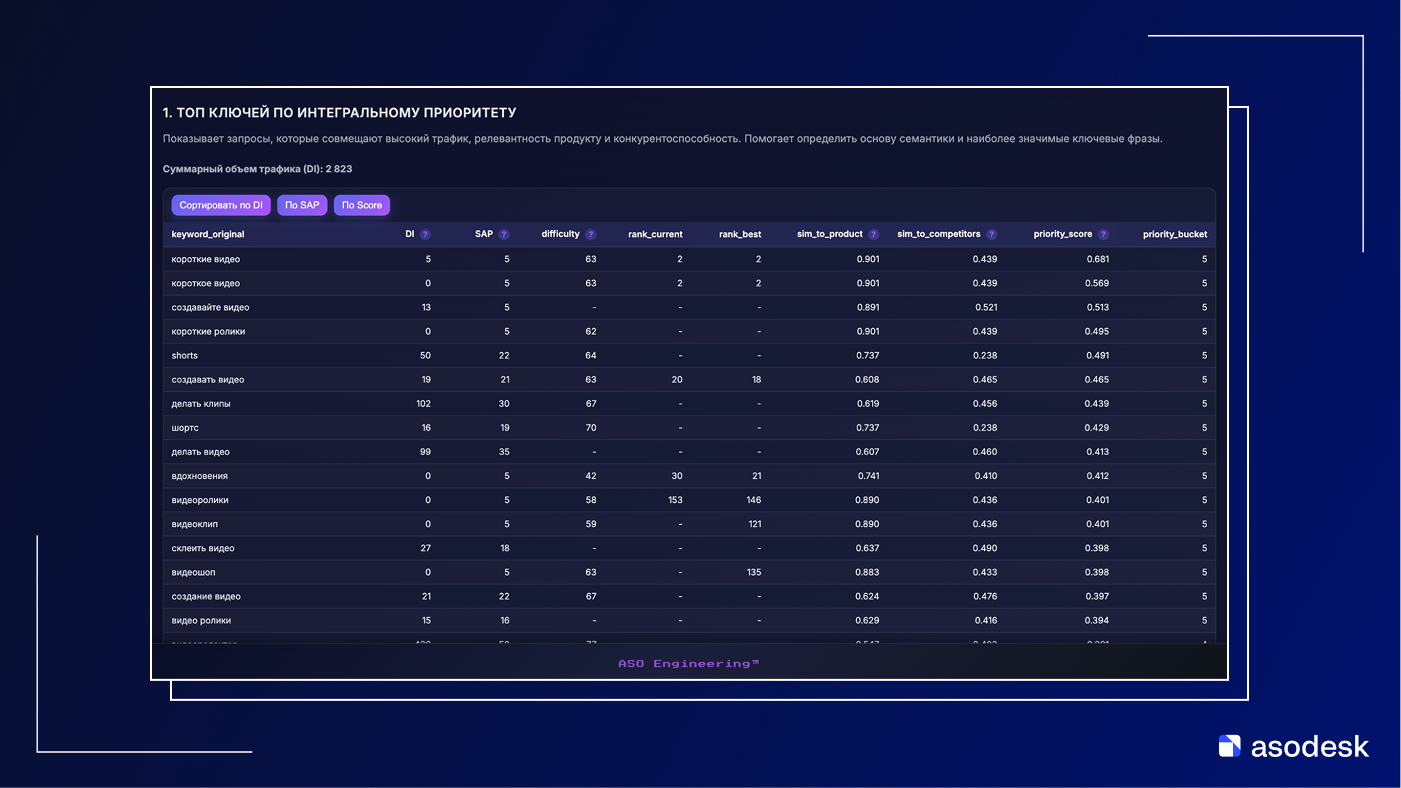
По сути, это просто таблица из трех колонок: список ключей, их ориентировочный трафик и условная сложность продвижения. Оценивать релевантность и приоритет использования каждого из этих ключей только по трафику и сложности в принципе невозможно. Не знаю, как это использовалось, но это реальный документ, который мне прислали.
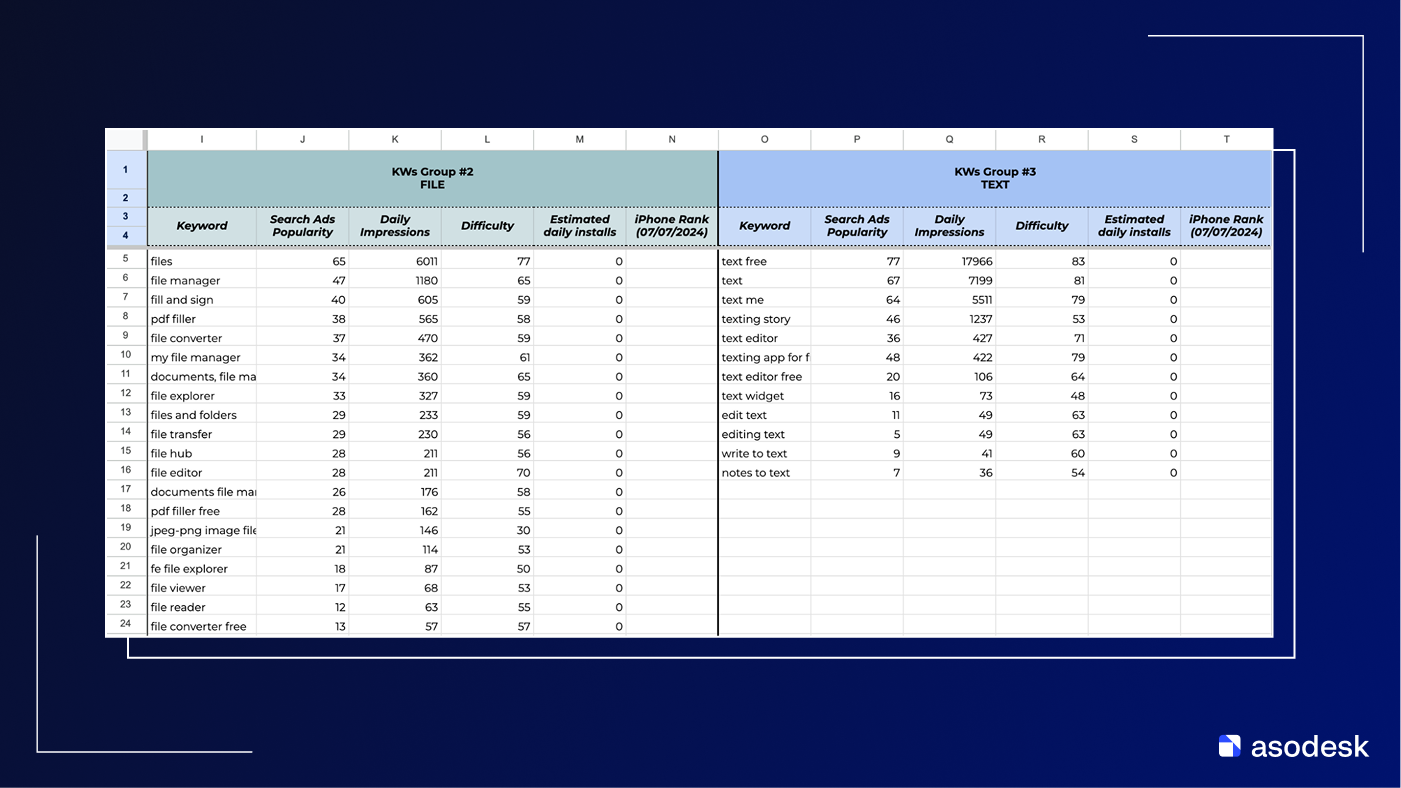
А вот так выглядит семантическое ядро 2024 года. Ключи распределены по группам, добавились дополнительные метрики. Появилась минимальная сегментация запросов по тематике и возможность оценивать не только сырой трафик, но и потенциальную установочную емкость кластера.
Но мы не видим, какие запросы фактически дублируют друг друга, какие описывают разные сценарии использования, какие тянут брендовый трафик, а какие — нет. Любое решение «какой ключ оставить, какой выкинуть, какой усиливать в метаданных» остается вопросом субъективной экспертизы, а не результатом анализа семантической структуры пространства запросов.
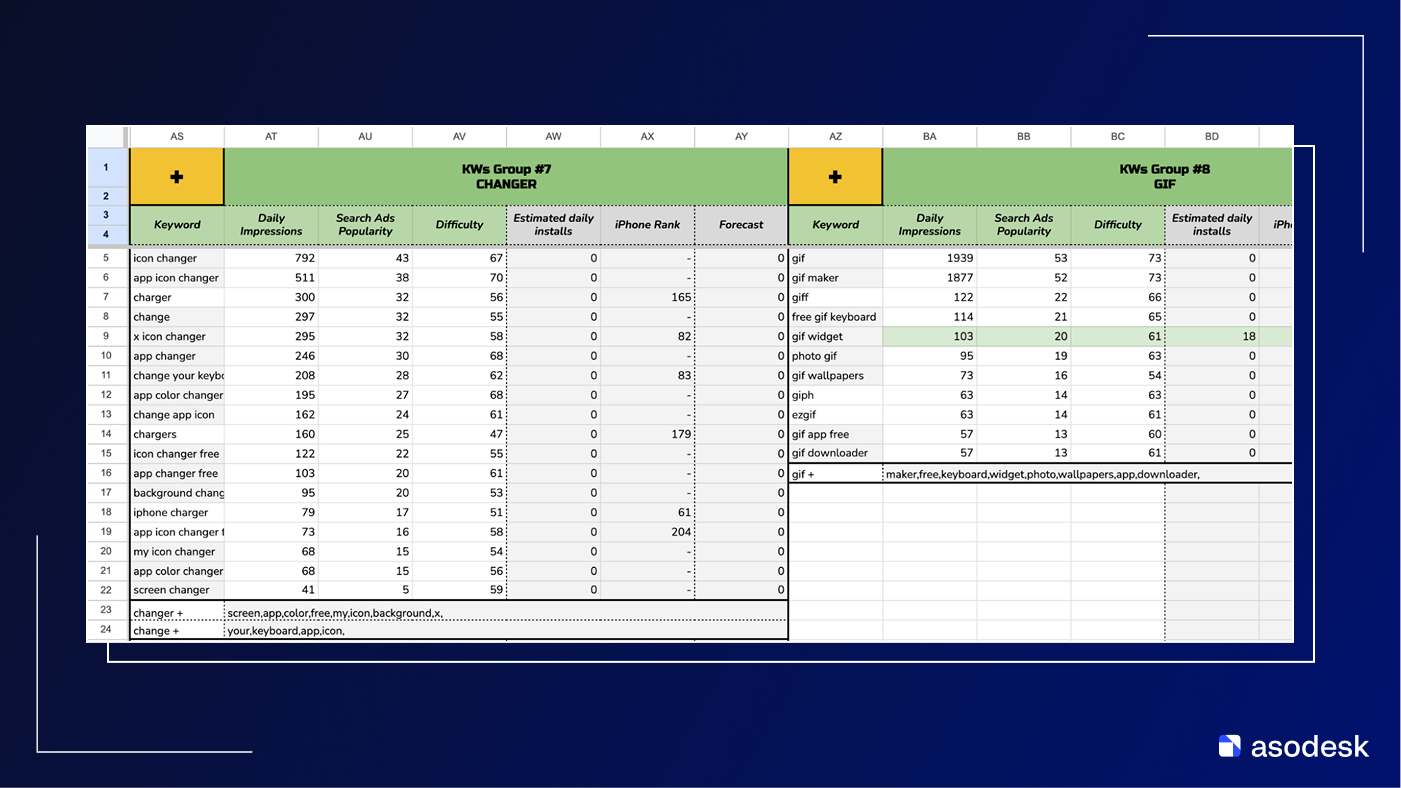
Пример ядра начала 2025 года для App Store, где специалист разбивает ключевые фразы на токены и комбинирует их между собой. По сути, это ручной «конструктор» из кусочков слов, который позволяет быстрее собирать поле Keywords, покрывая весь кластер.
Но принципиально подход остается тем же: все решения принимаются на уровне отдельных слов и их комбинаций (надо же все 100 символов заполнить). Токены подбираются по частотности и здравому смыслу эксперта, а не на основе реальной семантической близости запросов в общем пространстве.
Мы по-прежнему работаем с лексикой, а не с векторной моделью. Это уже более продвинуто, чем таблица 2021 года, но до полноценного семантического ядра такой таблице еще далеко.
Давайте немного освежим знания о том, как работает лексический и семантический поиск. Так как судя по комментариям которые мне присылали, не все поняли, о чем я писал в предыдущей статье. В этот раз разложу проще и с наглядными примерами.
Ключевые идеи о том, как работает поиск
В начале был лексический поиск – механизм, при котором поисковая система ищет точные совпадения слов запроса в тексте метаданных. Иными словами, если слово запроса никак не упомянуто в ваших метаданных, ваше приложение просто не появится в выдаче по этому запросу.
На этапе индексирования алгоритм отбирает кандидатов только по наличию слов. Отсюда исторически выросла практика сбора семантического ядра – подобрать и вставить популярные запросы (ключевые слова) в текст статьи/сайта/приложения, чтобы охватить максимальное число поисковых комбинаций.
В прошлый раз я приводил примеры для Google Play и App Store, но обошел стороной RuStore. Хотя по комментариям многим интересно, какой поиск там.
Возьмем для примера симулятор рыбалки. Первое, что сразу бросилось в глаза – очень много слов онлайн и по сети, хотя лексическая плотность у этих слов не такая высокая (около 2%).
Заходим в Asodesk, чтобы посмотреть по каким словам ранжируется приложение. Если кто не в курсе, то Asodesk – официальный партнер RuStore и все эти данные получает напрямую от них. Поэтому, этим данным можно доверять.
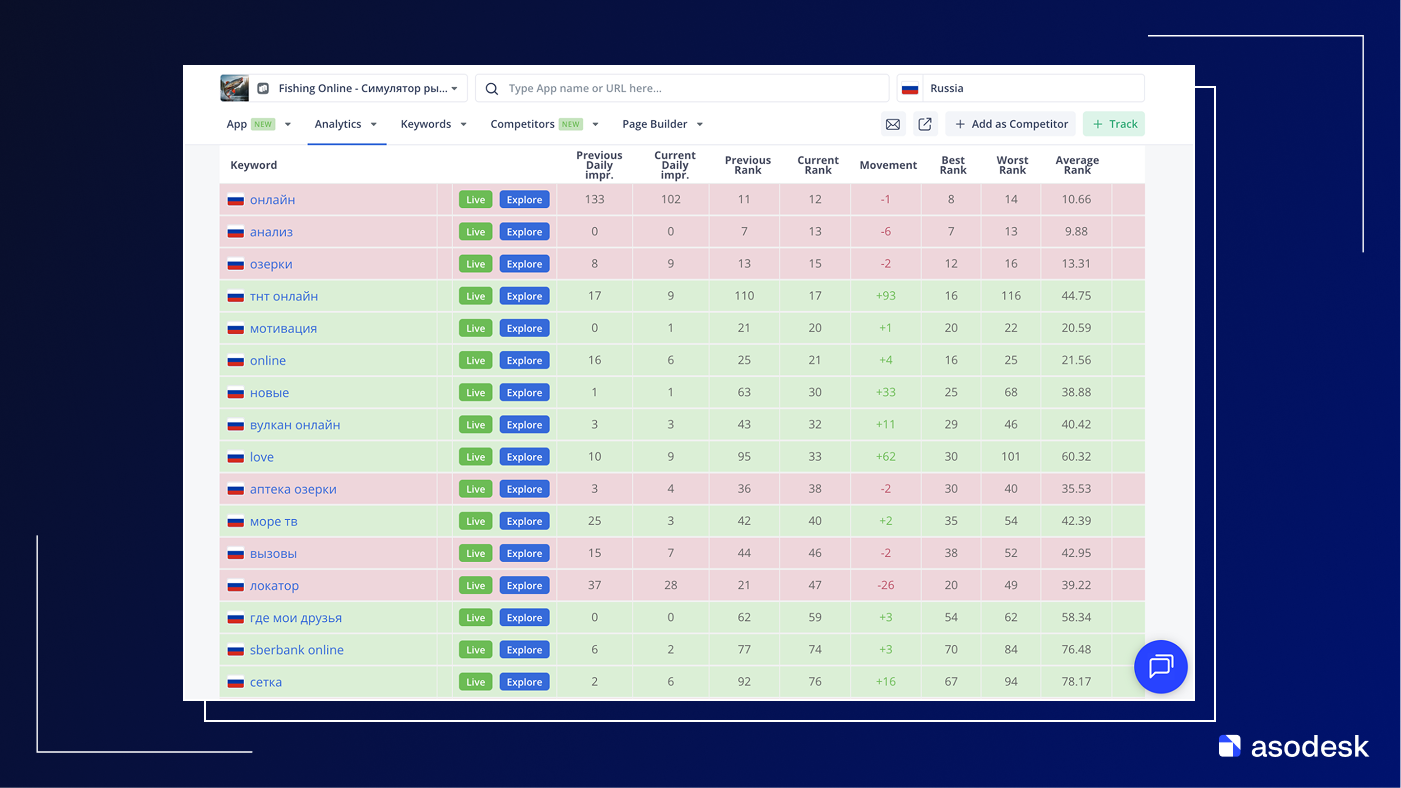
RuStore, судя по поведению, разбирает запросы на отдельные токены и ранжирует приложения по сумме совпадений, не требуя совпадения всех слов и не учитывая сам бренд как сущность.
В названии и описании игры несколько раз фигурируют токены online, онлайн, поэтому приложение автоматически попадает в выборку по любому запросу, где встречается это слово: от общего онлайн до тнт онлайн, вулкан онлайн, sberbank online и т.п. А слово озеро из полного описания он сопоставил с аптека озерки, море – с море тв.
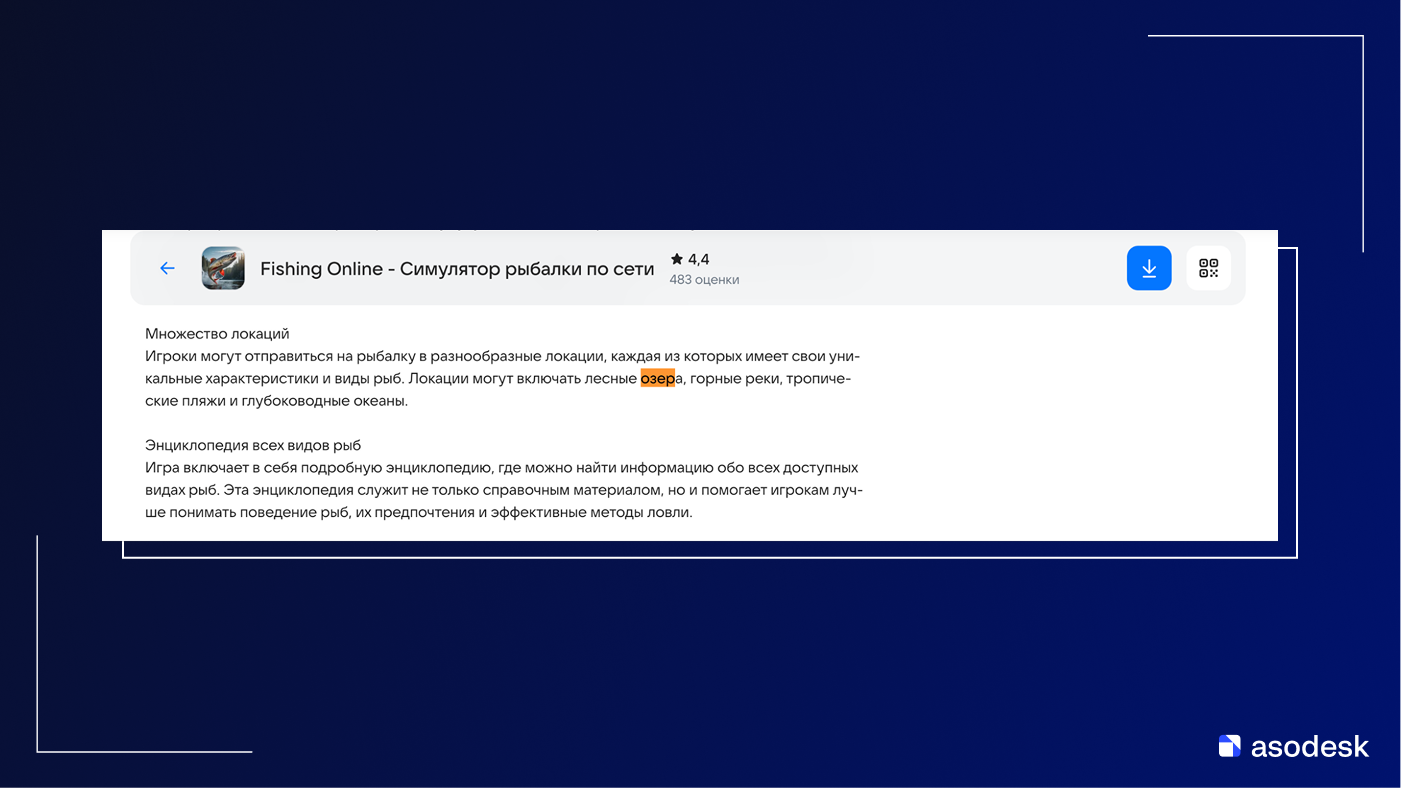
Есть совпадение по корню, значит приложение можно включить в выдачу по этому запросу. С точки зрения IR это чистый лексический поиск с грубой лемматизацией и без брендового слоя, отсюда весь этот мусор, который не может стать основной ядра. Но, на момент публикации статьи я могу уже ошибаться, так как стор развивается достаточно быстро. И что сегодня вижу, завтра может работать уже не так. Как минимум настроить пороги лемматизации — сравнительно простая задача. А внедрить брендовый словарь и проверить его на рабочей базе — вопрос короткого цикла разработки и тестирования.
И вот, потом настал 2025 год, когда и Apple, и Google открыто заявили о переходе к поиску по смыслу (Natural Language Search). Google Play в сентябре представил Guided Search – поиск по цели или идее, а не только по названию приложения или ключевым словам. Еще ранее, в мае, Apple объявила, что App Store научился понимать повседневный язык. Проще говоря, индустрия отходит от буквального совпадения к поиску по намерению пользователя.
Это называется семантический поиск или поиск по смыслу запроса. Такой поиск опирается на технологии обработки естественного языка: вместо того чтобы искать точные слова, алгоритм преобразует запрос и тексты приложений в некие смысловые представления (векторы) и сравнивает их.
При семантическом подходе система может показать результат, даже если в тексте приложения нет буквального совпадения с запросом – главное, что по смыслу описание приложения близко к тому, что спрашивает пользователь.
Но на практике современные сторы используют гибридные модели: сперва отбираются кандидаты лексически (по словам), а затем их ранжирование уточняется на основе семантических факторов и дополнительных сигналов.
Возможна и другая схема: параллельно выполняется два поиска – один по ключевым словам, другой по векторам – а потом списки результатов объединяются и перемешиваются с учетом релевантности каждого.
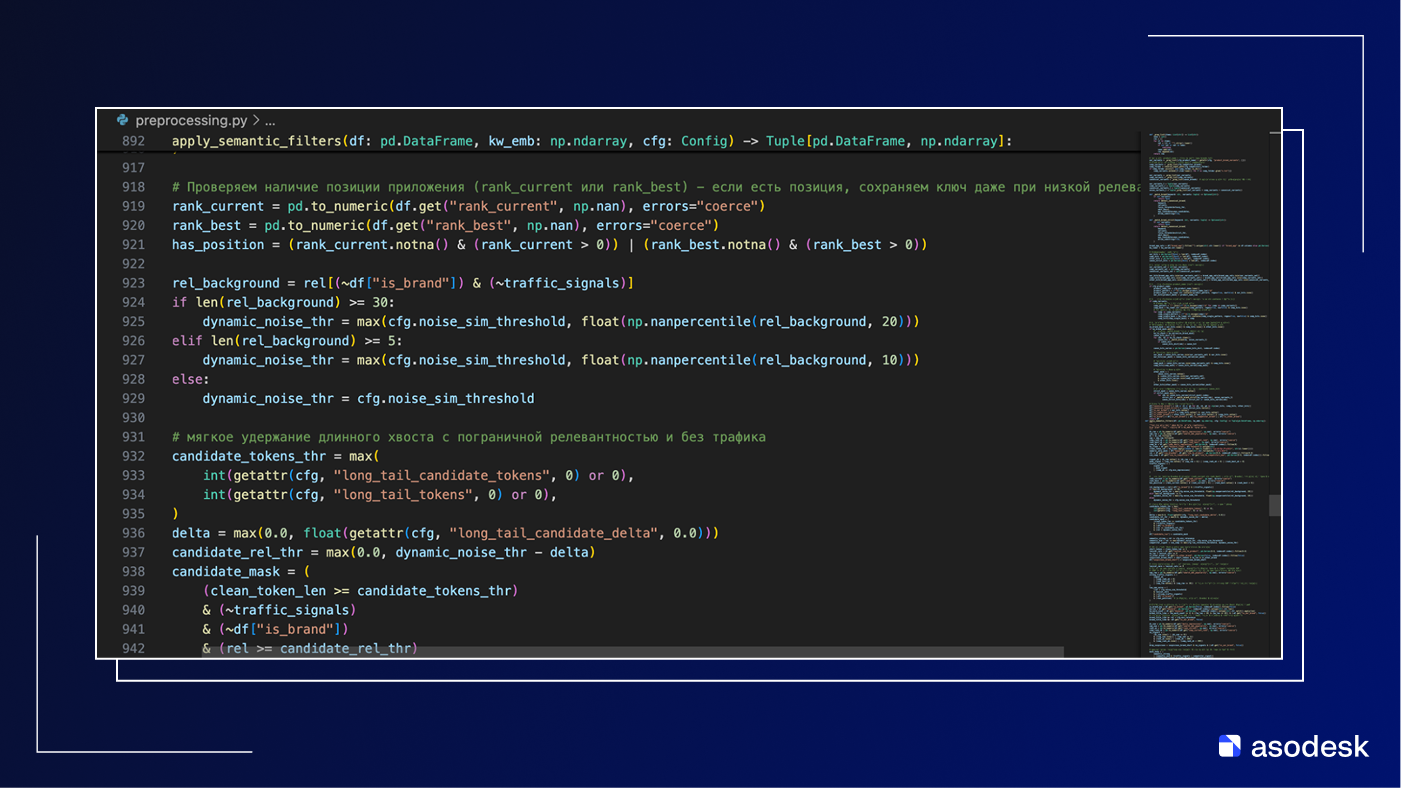
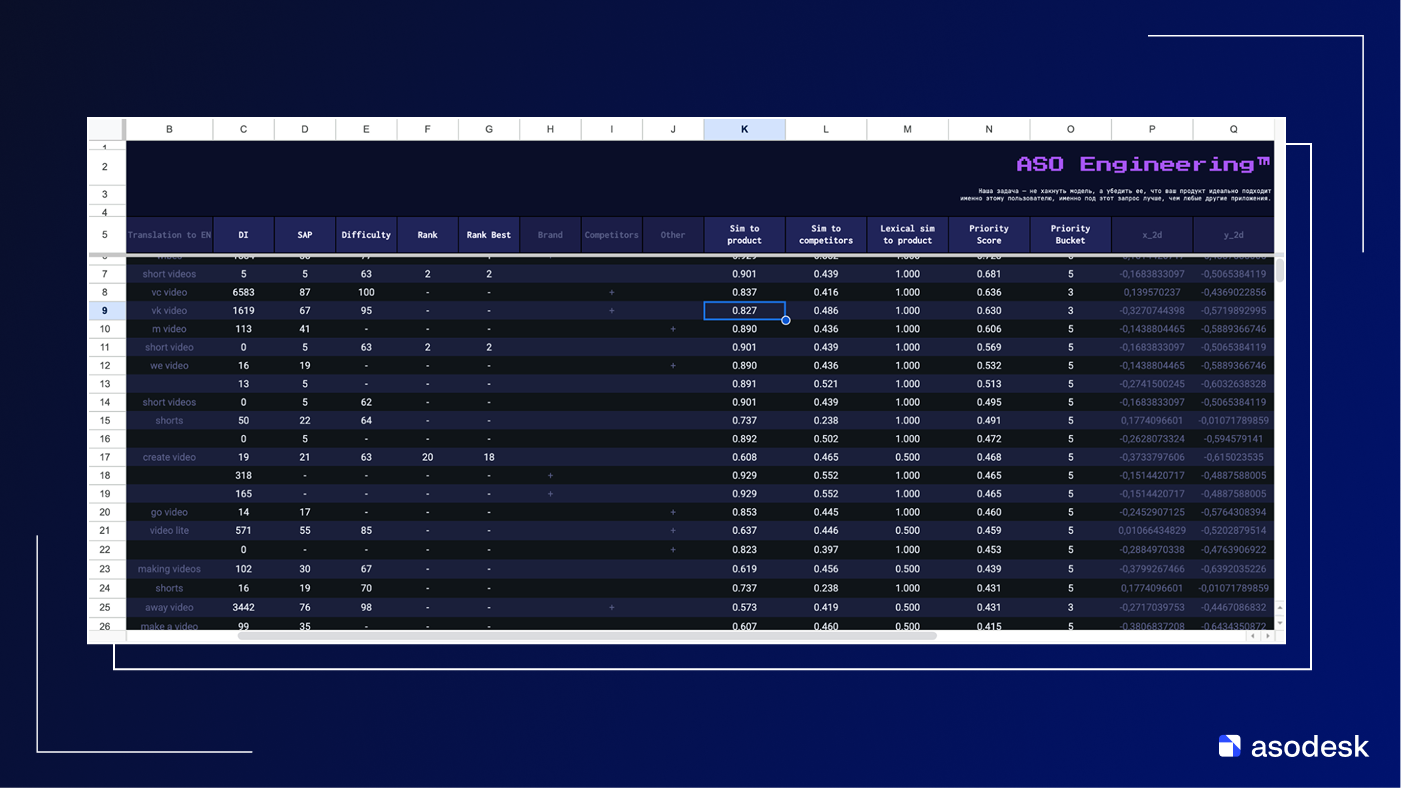
Похожую логику я реализовал как раз для отбора наиболее релевантных ключей. Сначала лексический слой: из всех строк выгрузки удаляются откровенный мусор, обрывки фраз, технические и нерелевантные запросы. Остается кандидат-сет из валидных ключей, с которыми есть смысл продолжать работу.
Дальше включается семантический слой. Для продукта и описаний конкурентов считаются эмбеддинги, по ним вычисляются метрики близости, добавляются сигналы спроса — DI, SAP, фактические позиции и наличие ранжирования у конкурентов.
Затем все это складывается в единую маску: семантически сильные ключи проходят сразу; ключи со средней релевантностью сохраняются, если по ним есть реальные данные спроса и видимости; ключи без смысла и без сигналов отбрасываются.
В результате итоговое ядро — это пересечение запросов, которые действительно близки к продукту по смыслу, и запросов, которые подтверждены поведением пользователей (в данном случае выгрузка дает нам информацию о ранге и установках).

Ключевые слова по-прежнему нужны – без них индексации не будет вовсе. Но одной индексации мало: нужно, чтобы ваше приложение еще и считалось релевантным по теме запроса.
Скептически настроенный читатель может возразить: «Мы же не знаем точно алгоритмы Apple и Google – откуда все эти выводы? Не являются ли они просто догадками автора?» Возражение удобное. Проблема только в том, что оно опирается на представление о поиске десятилетней давности и игнорирует уже публично обозначенные изменения в архитектуре.
Во-первых, Apple публично зафиксировала, что в App Store используется natural language search: в iOS 18.1 компания прямо продвигает формат «search the way you talk», когда пользователь вводит фразы уровня «apps to help me relax before bed». В новостных релизах Apple natural language search и App Store review summaries названы частью intelligent features сервисов, то есть базовым элементом стека.
Во-вторых, еще в 2019 году Google публично подтвердил использование BERT в веб-поиске для более точного понимания запросов и улучшения ранжирования. Это означает, что в ключевых поисковых продуктах компании нейросетевые компоненты применяются давно. Поэтому методически странно ожидать, что внутри стора внезапно работает исключительно простая лексическая схема уровня BM25, без дополнительных NLP-сигналов. Точные детали внутренних алгоритмов мы не знаем, но практическая логика такова: современный поиск почти всегда комбинирует лексическое совпадение (слова) и семантическое соответствие (смысл), а качество выдачи определяется тем, какие сигналы доминируют и как настроены их веса.
В-третьих, важно понимать базовую вещь: современные NLP-модели не являются уникальными для каждого стора. Процесс работы с естественным языком в поисковых системах сегодня устроен типовым образом и почти везде следует одной и той же архитектурной логике.
Это означает простое следствие: когда мы говорим про NLP в поиске стора, мы обсуждаем не предположение о некоем эксклюзивном «секретном алгоритме», а стандартный индустриальный класс решений. Разница между платформами не в том, есть ли там работа со смыслом, а в том, как именно настроены пороги, веса и приоритеты между лексикой, семантикой и поведением.
Давайте структурно разберем, как работает эта логика в идеальной архитектуре:
1. Индексация: прежде всего, стор индексирует текст всех приложений. Метаданные разбиваются на токены – грубо говоря, слова и их части. Каждому слову соответствует список приложений, где оно встречается. Этот инвертированный список позволяет быстро найти кандидатов по слову запроса. Одновременно происходит предварительное взвешивание: где встретилось слово (в названии – вес больше, в описании – меньше и т.п.), сколько раз повторяется (учитывая порог насыщения), каков общий вес текста и т.д. Словом, формируется некая «база кандидатов» и базовые веса по лексическому соответствию. Это только как самый понятный вариант реализации этапа индексации
2. Анализ запроса: когда пользователь вводит запрос, современная система не ограничивается тривиальным сопоставлением слов. Во-первых, она определяет язык запроса. Во-вторых, запрос проходит через NLP-процессинг: токенизацию (разбиение запроса на слова и значимые единицы) и лемматизацию (приведение слов к базовой форме: множественное число к единственному, разные падежи к начальной форме и т.д.).
3. Создание векторного представления: вот тут начинается самое интересное. Вместо того чтобы просто искать эти слова, алгоритм пропускает слова запроса через модель машинного обучения, которая превращает их в числовые векторы, скажем, из 768 чисел (как в BERT) или другой размерности, который кодирует значение слова с учетом контекста.
4. Семантический поиск кандидатов: теперь задача – найти приложения, которые по смыслу соответствуют запросу. Каждое приложение (точнее, его текстовое описание) тоже может быть представлено вектором – аналогично запросу. Система сравнивает вектор запроса с векторными представлениями всех приложений, чтобы найти самые похожие. Детали не так важны. Важно понимать, что технически задача «найти топ-100 близких по смыслу приложений» решается легко и просто с помощью графов или деревьев.
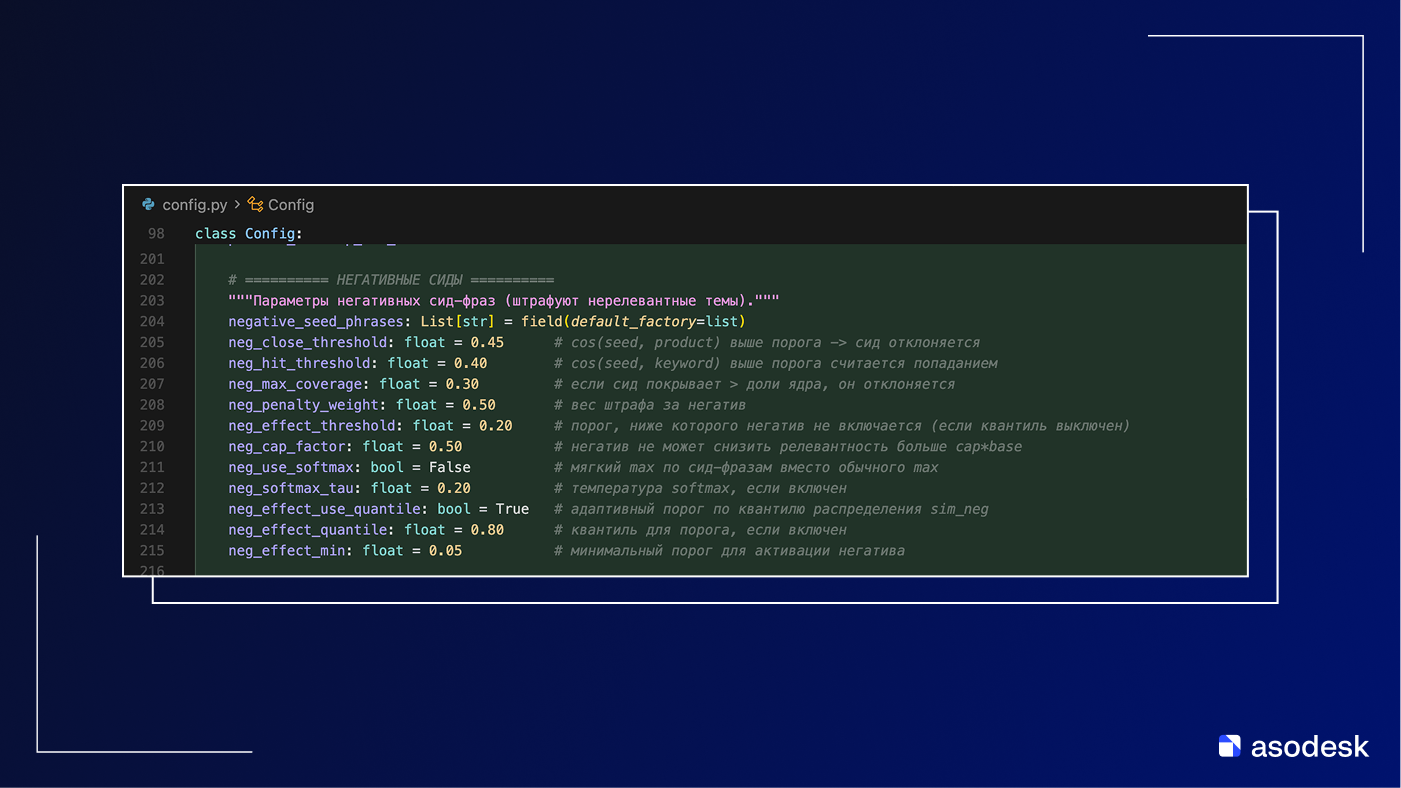
Ранее я показал, что получил очищенное от мусора семантическое ядро. Следующим этапом нужно будет определить релевантность каждого запроса нашему приложению. И тут как раз мы будем использовать SentenceTransformer. Нам достаточно высчитать семантическую близость к описанию продукта и конкурентов через косинусное расстояние, что обеспечит точное понимание смысловой релевантности.
5. Комбинирование с лексическим фильтром: помните, параллельно у нас есть список кандидатов по лексическому соответствию (п.1). В гибридной модели эти два списка объединяются. Самый простой способ – объединить и отсортировать всех кандидатов по какому-то единому скору, который учитывает и текстовое совпадение, и семантическое сходство. Более сложный способ – взять пересечение: например, требовать, чтобы кандидат содержал хотя бы одно из слов запроса, а семантика уже доранжирует.
У Apple, судя по всему, используется частичное объединение: если запрос содержит уникальные идентификаторы (названия брендов, имена приложений), они не должны потеряться. Поэтому, вероятно, сначала отбираются все точные соответствия важных слов, и добавляются результаты семантического поиска для разнообразия выдачи. Затем они все ранжируются вместе. Получается, что ключевые слова по-прежнему важны для индексации, но финальный порядок все чаще зависит от смысловой близости и поведенческих факторов. Да, кто не в курсе – App Store тоже учитывает поведенческие факторы.
Что уж говорить про сторы, если сейчас даже в маркетплейсах есть сложная схема ранжирования:
6. Учет поведенческих сигналов и качества: на этом этапе поисковая система знает, какие приложения могут быть релевантны запросу. Далее вступают в игру дополнительные факторы. Современные алгоритмы используют сотни параметров при ранжировании. Например, если приложение имеет высокий Retention (удержание пользователей) или хорошие оценки, это сигнал качества – ему может даваться бонус. Если наоборот, приложение часто вылетает (crash rate выше конкурентов), это понижает его в результатах. Отслеживаются и поведенческие сигналы по самому поиску: клики по приложению в выдаче, установки, быстрота удаления после установки, доля пользователей, открывших приложение после поиска и оставшихся активными – все это помогает понять, насколько результат удовлетворяет запрос пользователя. В некоторых поисковых патентах Google описаны механизмы, когда система логирует поведение и повышает те результаты, по которым были хорошие показатели взаимодействия. Таким образом, два приложения с равной семантической релевантностью могут занять разные места: у кого метрики лучше – тот выше. И игра со словами тут не поможет.
Далее могут идти этапы персонализации, какие-то дополнительные бустинги, корректировки коэффициентов и т.п. Из практики есть интересный кейс.
2024 год. Летом известный бренд выпускает новое приложение. Осенью к нам приходит инди-разработчик с приложением практически повторяющее приложение того бренда. Приложение крупного бренда без явной ASO-оптимизации довольно быстро оказывается в бакетах 1–10, тогда как ноунейм на тех же запросах остается за пределами топ-20. Почему?
Во-первых, бренд и аккаунт разработчика выступают сильным сигналом качества. У стора уже есть история других продуктов этого разработчика. Для алгоритма это готовая вероятность того, что новый релиз тоже не окажется мусором. Поэтому стартовый скор у бренда выше, даже до накопления данных по новому приложению.
Во-вторых, брендовые и околобрендовые запросы очень быстро формируют поведенческий профиль. Пользователи, знакомые с брендом, вводят его в поиск, не редко кликают по новому приложению, устанавливают и не удаляют его сразу. Для системы это сильный сигнал: по этим запросам кандидат обеспечивает высокий CTR и конверсию, значит его можно поднять в верхние бакеты и по более общим ключам той же тематики.
В-третьих, колд-старт для ноунейм-приложения решается в «безопасном режиме». У него нет ни брендового якоря, ни собственной истории, поэтому гибридная модель отдает ему только ограниченный трафик на глубине выдачи и по хвостовым запросам. Пока не накопятся достаточные поведенческие данные и стабильные метрики качества, у алгоритма просто нет оснований поднимать сразу такой кандидат в топ-10. Но, чтобы избежать эффекта «сильные становятся еще сильнее», иногда даже такие приложения закидывают в топ-1, что и произошло в день релиза.
Да, конкретные формулы Apple и Google закрыты, но общие принципы известны и подтверждены их же заявлениями. Это не догадки, а экстраполяция очевидных трендов.

Да, сторы внедряют NLP и семантические механики — это естественный этап развития поисковых систем. Но в поиске внутри сторов критичны задержки и масштабируемость, поэтому на практике используются не «идеальные» по размеру и сложности модели, а оптимизированные решения. В результате мы имеем дело не просто с усеченными моделями, а с балансом качества и скорости, обеспечивающим стабильный пользовательский опыт на массовом трафике.

Так совпало, что Apple анонсировала использование NLP в момент, когда вайб-кодинг стал настолько распространен, что в App Store появилось на 24% больше приложений, чем в прошлом году. Согласно данным Appfigures текущий год стал рекордным по количеству выпущенных приложений за последние 9 лет. Коллеги из канала Mobile Development by AppTractor пишут:
«В App Store происходит ренессанс, основанный на возможности успеха. Всплеск 2025 года — это не мимолетная мода. Это результат нескольких различных факторов, которые делают разработку приложений рентабельной для совершенно нового класса предпринимателей».
Это дополнительно повышает сложность внедрения NLP и требования к качеству ранжирования, чтобы пользователи продолжали получать релевантные результаты. Однако стратегический вектор очевиден: по мере оптимизации моделей, роста вычислительных возможностей и накопления данных о поведении пользователей NLP в поиске сторов будет использоваться все более полно и станет стандартом качества, а не экспериментальной надстройкой.

Семантические ядра в век векторного поиска
Если традиционный поиск опирается на инвертированный индекс (список слов) и представление текста как набора токенов, то семантический поиск опирается на представление текста как точки в пространстве.
Представим, что каждый запрос и каждый текст описания приложения – это точка в многомерном пространстве. Близкие по смыслу запросы будут лежать рядом, даже если у них нет общих слов.
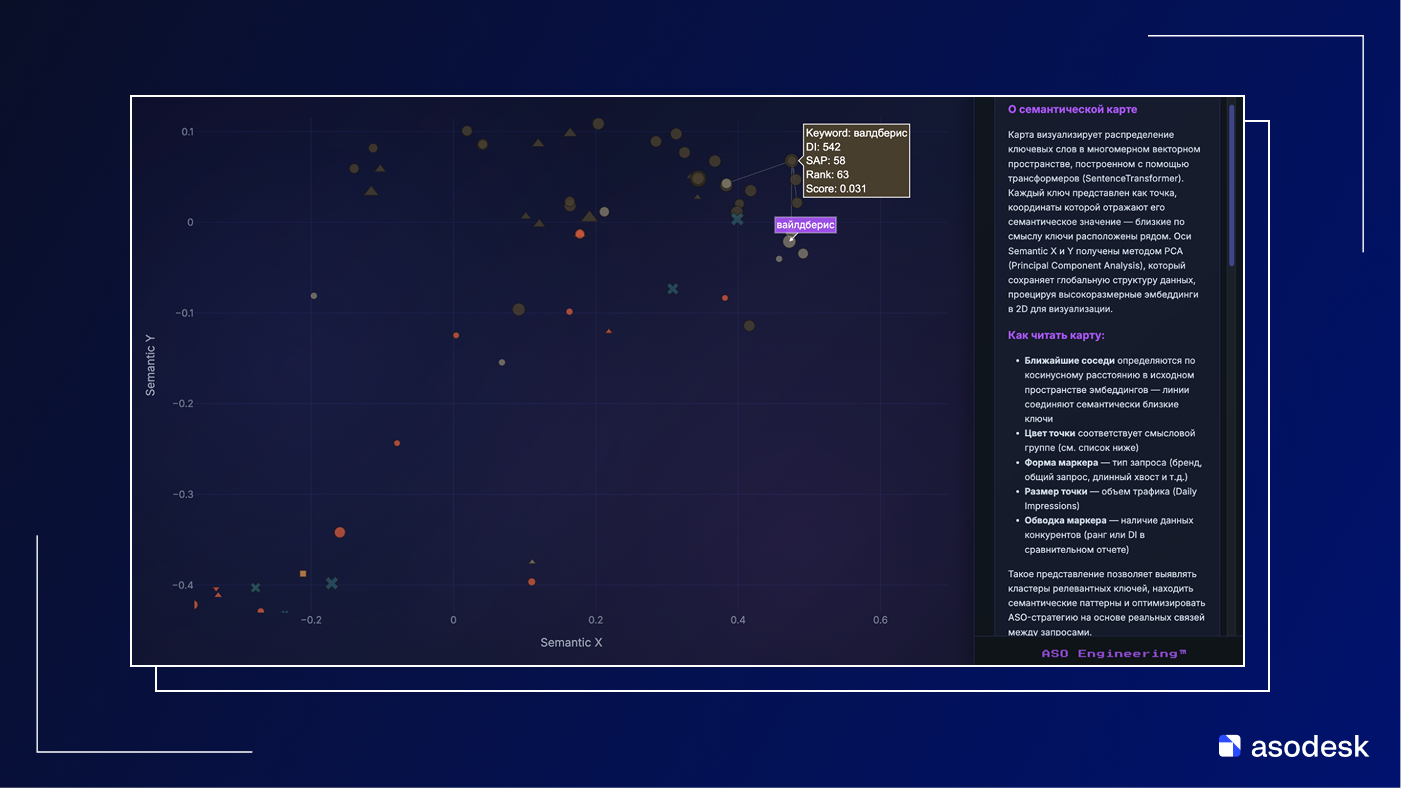
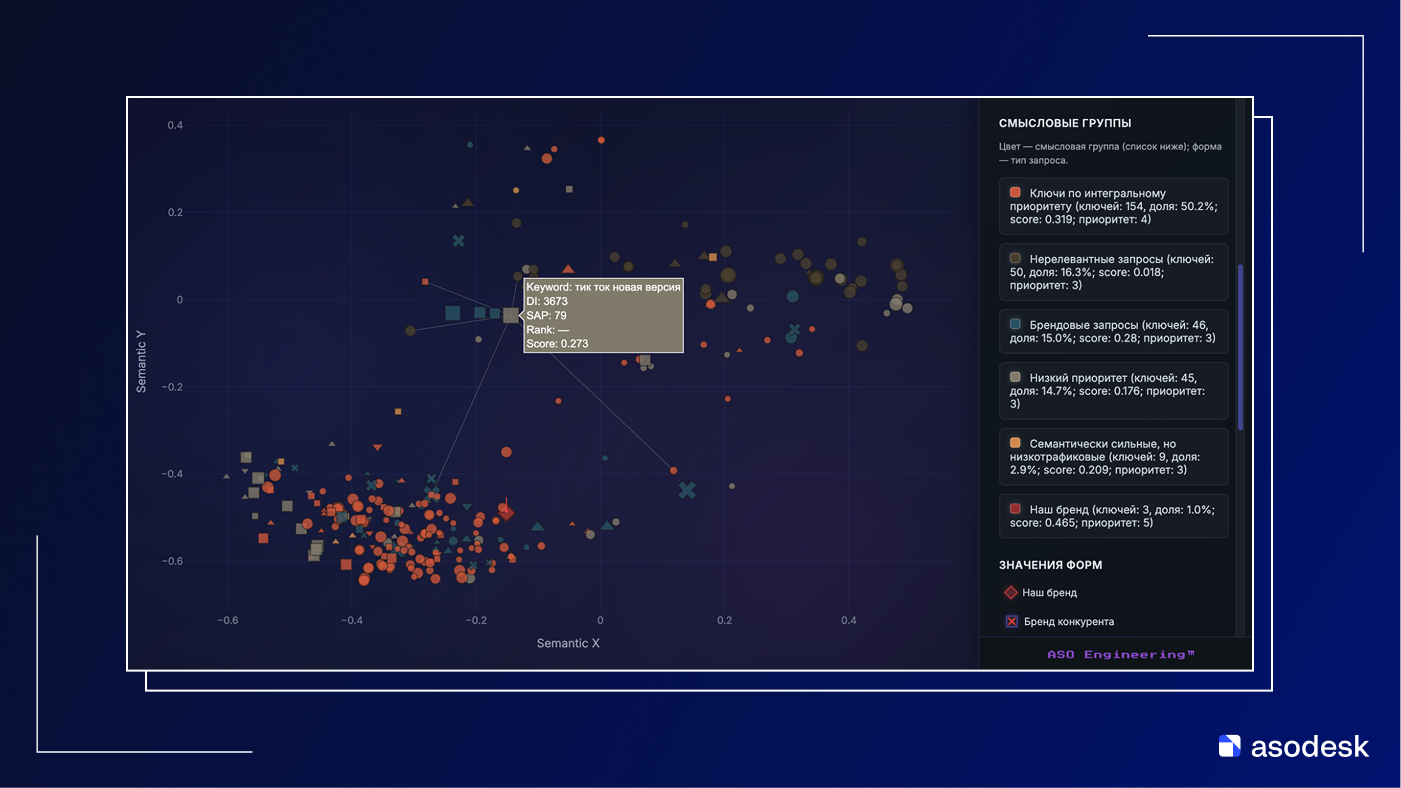
На первом скриншоте видно кластер брендовых запросов Wildberries: валдберис, вайлдберис, вилбириз и другие опечатки. Написание разное, общие токены могут не совпадать, но модель по контекстам понимает, что это один и тот же брендовый запрос и сжимает все эти ключи в плотную группу в правом верхнем углу карты. При этом кластер заметно оторван от остального облака запросов приложения – по эмбеддингам он живет в своей «зоне бренда», далекой от задач целевого продукта.
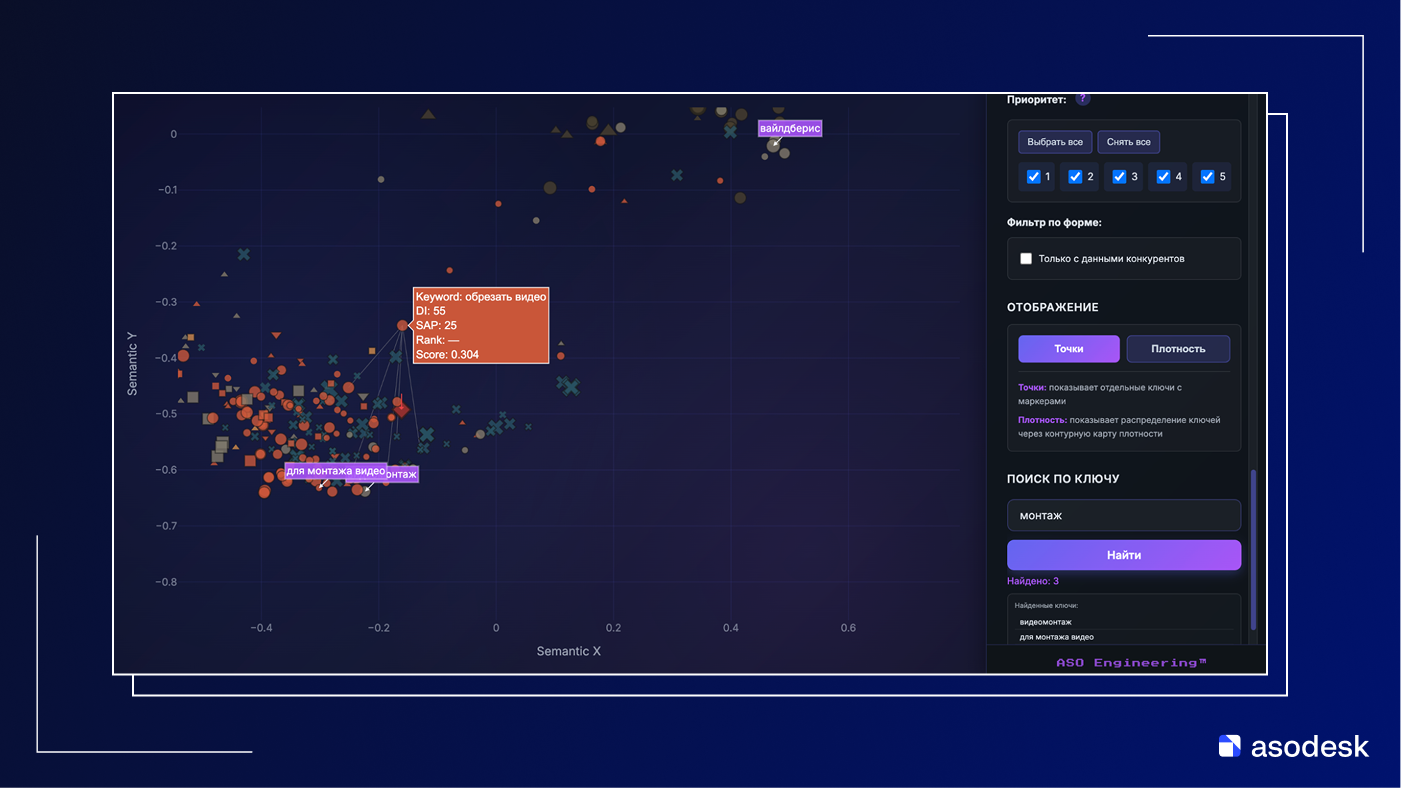
На втором скриншоте показан другой участок пространства – кластер запросов про монтаж видео. Вокруг подсвеченного ключа обрезать видео сгруппированы запросы для монтажа видео, видеомонтаж и им подобные. Формулировки разные, но все они описывают один сценарий: редактирование и обработка роликов.
Модель фиксирует эту близость и размещает ключи рядом, соединяя их линиями как ближайших соседей. В результате на карте мы видим не просто список слов, а реальные смысловые поля: отдельный остров брендовых опечаток Wildberries и отдельное облако запросов про монтаж.
Именно так работает семантический поиск на эмбеддингах: он ориентируется не на совпадение слов, а на расположение точек в общем векторном пространстве.
Имея эмбеддинги для десятков или сотен запросов, мы можем увидеть их реальную семантическую структуру прямо на карте. На скриншоте ниже вокруг брендового запроса яндекс ритм виден небольшой остров ближайших соседей: ключ шоппинг и ряд других запросов про покупки и товары. Модель поместила все эти точки рядом, потому что в векторном пространстве они описывают один и тот же смысловой кластер (исходя из меты этого приложения).
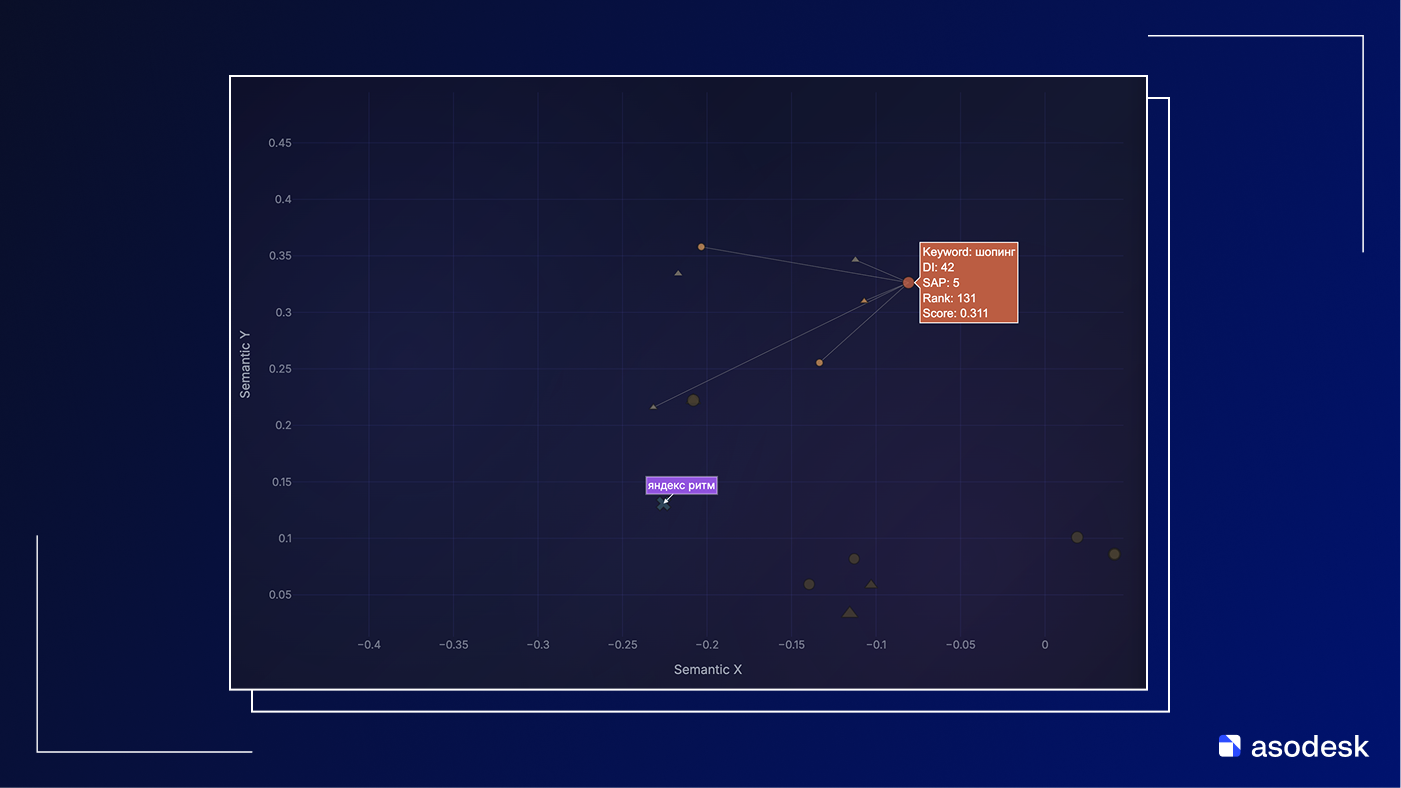
Расстояния между эмбеддингами внутри этого кластера малы, поэтому на карте точки связаны линиями как ближайшие соседи. При этом сам кластер заметно отделен от других важных групп запросов – их векторы лежат в других областях пространства. Визуализация сразу показывает, как брендовый запрос яндекс ритм оказывается встроен в поле шоппинга. И именно так алгоритм его читает только из-за того, что приложение описано не как короткие видео.
Чем все это полезно ASO-специалисту на практике?
На карте сразу видно, какие запросы дублируют друг друга по сути. Брендовый кластер Wildberries с десятками опечаток и вариаций в пространстве сжимается в одну плотную группу. Внутри нее нет принципиальной разницы между формулировками: с точки зрения модели это один и тот же брендовый запрос. Значит, в ядре достаточно оставить один-два контрольных ключа, а остальное убрать.
Точно так же читается кластер запросов про обработку видео: обрезать видео, для монтажа видео, видеомонтаж и другие соседние точки. Карта показывает, что это один сценарий использования — монтаж. Здесь уже другая задача: не вычищать, а отобрать оптимальный набор ключей внутри смыслового поля. Можно оставить сильные по трафику формулировки, а второстепенные синонимы использовать точечно, чтобы не занимать место в метаданных.
Отдельный пример — зона вокруг брендового запроса яндекс ритм. Вокруг него собирается кластер запросов шоппинг и других ключей про покупки и товары. Но тут вопрос к асошнику: этого ли он добивался своей метой?
Чрезмерная набивка меты околорелевантными ключами снижает релевантность приложения. Модель просто не поймет, о чем ваше приложение, если вы перечислите вообще все. Вектор должен уверенно отражать основной интент.
Поэтому в семантическом ядре важна чистота групп: лучше каждую группу раскрывать в тексте отдельно и связно, чем пытаться уместить все кластеры разом несколькими словами. Вот тут на помощь и приходят кастомные страницы и кросс-локали.
Как собрать семантическое ядро в векторном пространстве
Теперь разложим все это в пошаговую методику, чтобы сквозь весь описанный шум у вас наконец-то появилось понимание «а делать то что?».
1. Сбор исходных данных (поисковых запросов). Соберите максимальный список поисковых запросов, релевантных вашей тематике. Это могут быть подсказки из App Store и Google Play, популярные запросы из различных источников, запросы конкурентов, словосочетания из отзывов пользователей и проч. В идеале включите разнообразные формулировки: и короткие (1-2 слова), и длинные фразы в стиле вопросов или целей. Пусть список будет большим – десятки тысяч запросов, если возможно. Чем шире охват, тем лучше для анализа пространства.
2. Получение эмбеддингов. Далее пропустите все эти фразы через модель эмбеддинга. Вы можете воспользоваться готовыми моделями – например, SentenceTransformer. На выходе у вас должен получиться набор векторов – по одному на каждую фразу. В таком пространстве близкие по смыслу запросы будут иметь близкие координаты. Стоит нормализовать векторы (обычно модель сама выдает нормализованные или их приводят к единичной длине, чтобы косинусная близость была непосредственно скалярным произведением).
3. Построение графа близости. Полезным промежуточным шагом является построить граф или хотя бы вычислить ближайших соседей для каждого запроса. Например, для каждого эмбеддинга найти 20-50 самых близких к нему (по косинусу) среди остальных и соединить их как связанных узлов. Почему граф? Потому что тематические группы запросов образуют плотные компоненты в этом графе – по сути, кластеры. Можно использовать алгоритм HNSW (метод приближенного поиска ближайших соседей) или аналогичный, чтобы ускорить поиск соседей даже в десятках тысяч точек. В итоге у вас будет понимание, какие запросы тяготеют друг к другу.
4. Кластеризация запросов. Теперь нужно выделить группы – кластеры – семантически похожих запросов. Существует множество методов: от простого DBSCAN (кластеризация на основе плотности точек) до кластеризации на графе (поиск сообществ, например алгоритм Louvain или Chinese Whispers) либо K-means на векторах. Цель – сгруппировать близкие запросы вместе. При хорошем подходе кластеры сами обнаружат неожиданные синонимы и варианты, о которых вы могли не догадываться.
5. Приоритизация кластеров (оценка потенциала). После кластеризации у вас может получиться, скажем, 100–200 кластеров (в зависимости от объема ядра и тематики). Не все они одинаково важны. Здесь пригодится классическая частотность и конкурентность – то есть оценить, какой совокупный поисковый трафик стоит за каждым кластером. В итоге составьте приоритеты: какие темы для вас самые ценные и перспективные. Это поможет фокусироваться на них при оптимизации.
6. Подбор ключевых фраз и оптимизация под кластеры. Теперь, когда у вас есть кластеры, вы можете для каждого придумать, как ваше приложение должно быть представлено, чтобы по этой теме быть релевантным. Смысл в том, что вы оптимизируете текст не под одно слово, а под всю группу запросов, стараясь употребить формулировку, которая покрывает общий интент.
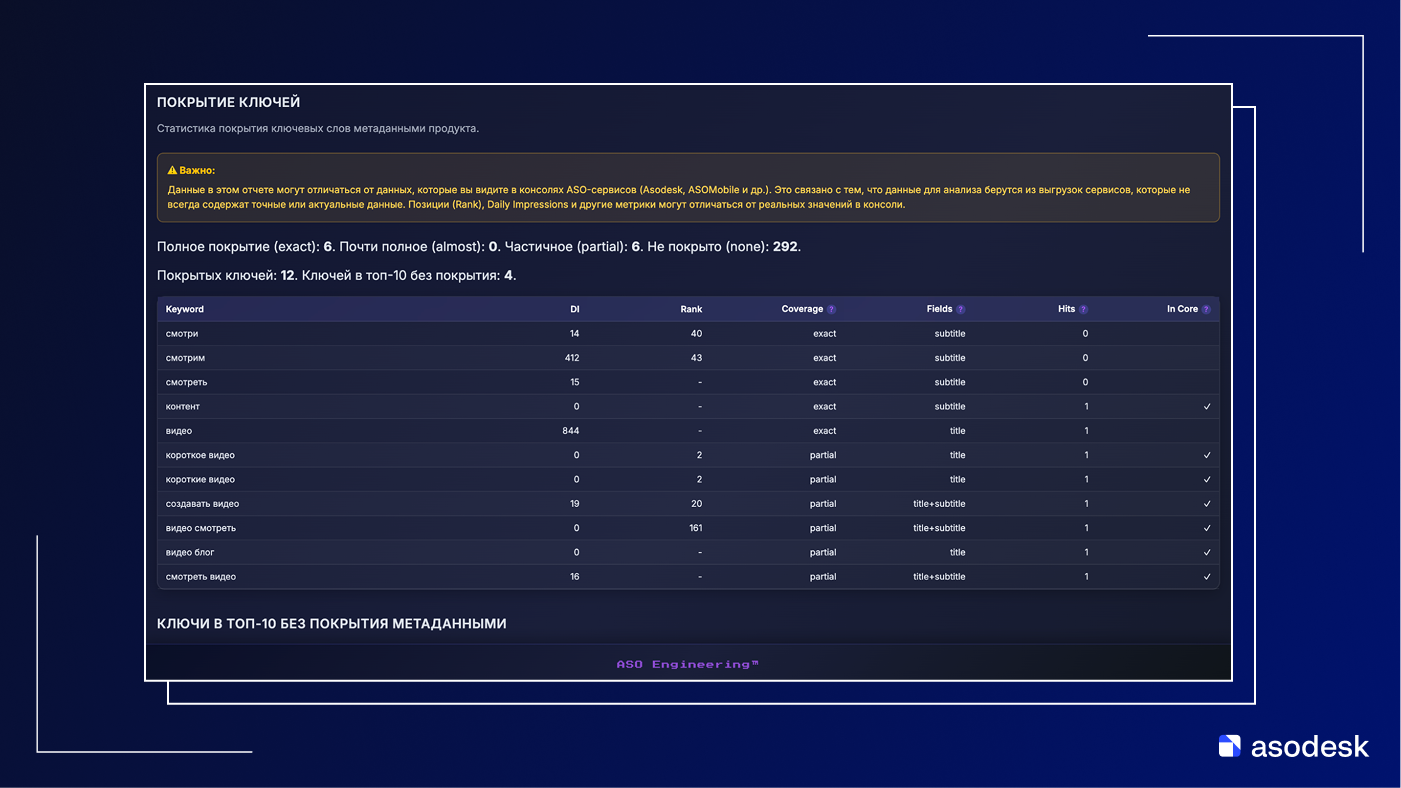
7. Визуализация и проверка покрытия. Полезно визуализировать ваши кластеры и текущее положение приложения (та самая карта, которая сопровождает эту статью). Можно сделать двумерную проекцию (например, через UMAP/T-SNE) всех запросов, отметить кластеры цветами и отметить, какие кластеры вы уже охватываете текстом. Такая карта сразу покажет, есть ли у вас пробелы. Визуализация делает семантическое ядро наглядным: вы видите тематику и объем запросов по ней. Потому что без визуализации мы получим выгрузку с координатами, которые по сути вам ничего не дадут.
Это новый процесс работы с семантикой. Он может сочетаться с продуктовой аналитикой: например, вы можете сопоставить кластеры с разными сегментами вашей целевой аудитории или с разными юзкейсам внутри приложения. Таким образом, семантическое ядро становится не просто списком слов, а инструментом продуктового планирования: вы видите, что интересует пользователей, на каком языке они формулируют проблемы, и адаптируете продукт (или хотя бы его позиционирование) под это.
***
Вас наверняка заинтересовали скриншоты приложения, которые сопровождают эту статью. Поделюсь с вами упрощенной моделью, которую вы сможете реализовать самостоятельно даже на своем ноуте с 8 Гб оперативки.

Остались вопросы? Вы можете всегда написать мне в Telegram @avtrener.
***
Напоследок отмечу, что по моим тестам текущая архитектура App Store и Google Play пока не выглядит полностью стабильной и зрелой. При повторных ежемесячных проверках видно, что качество выдачи то приближается к ожидаемой модели, то заметно откатывается. Это похоже на режим активных бесконечных экспериментов: команда поиска тестирует гипотезы, корректирует параметры, внедряет улучшения и откатывает изменения, которые ухудшают результат. Где-то что-то чинят, но и где-то ломают (именно так у меня проходил этап создания пайплайна, который описал в статье). В моменты таких откатов мы снова видим привычные паттерны ранжирования.
Вот пример, что было в сторах на момент анонса весной 2025 года:

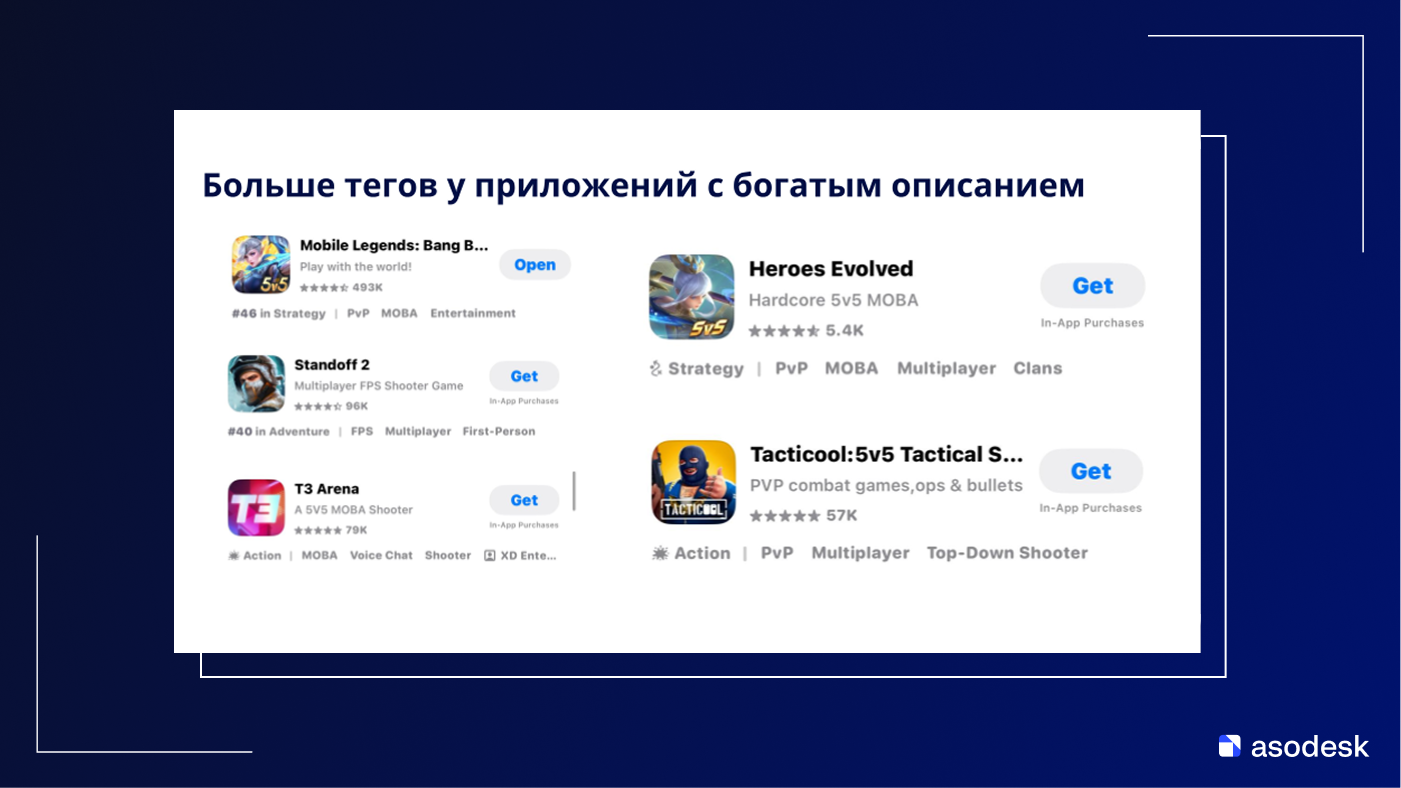
Интересный кейс Mini Mini Farm: Apple присвоила тег Island на основе полного описания, хотя в индексируемых метаданных этого ключа нет, поскольку для меты он нерелевантен.
Farming Simulator 18: тег был присвоен по ключу из полного описания. Почему именно этот функционал был выделен среди более релевантных для приложения формулировок, остается загадкой. Вероятно, система выбрала термин с наибольшим семантическим весом для категории (условный аналог логики IDF из примера выше) или как отличимый маркер сценария использования.
И результат первого теста работы с полным описанием в App Store:

Но прошло полгода и это работает уже не так. Давайте вернемся к этой статье в следующем году и посмотрим, в каком направлении тронулся лед.
Для ASO-специалиста это вызов, но и возможность. Нужно принять тот факт, что развитие поисковых систем не остановилось на BM25. Те, кто уже сейчас перестроят подход к семантическим ядрам – начнут думать категориями интентов – получат фору.
Семантическое ядро должно быть действительно семантическим и не важно, что доминирует сейчас лексика или семантика. Ядро должно отражать разнообразие путей, которыми пользователь может описать свою цель, и в то же время оставаться сфокусированным на этих целях.
В эпоху dense retrieval, semantic similarity, ANN и прочих умных штук побеждает не самый хитрый взломщик поиска, а тот, кто может сделать так, чтобы приложение было понятно машинам и ценно людям.










